LLMInference_Survey_Note
本文是一篇现阶段的大模型推理综述调查,主要贡献:
- 系统性地整理了最新的(2024.5)推理加速技巧,如model compression (e.g., quantization), algorithm improvements (e.g., speculative decoding), and both system and hardware-level enhancements (e.g., operator fusion)
- 提出一个基于 Roofline 模型的框架,可以通过此模型分析各方法对内存访问与计算的影响,这提供了对模型实际部署中的指导,如内存需求、计算瓶颈及硬件选择问题
- 开源了分析工具 LLM-Viewer
1 Delve into LLM Inference and Deployment
1.1 LLM Inference
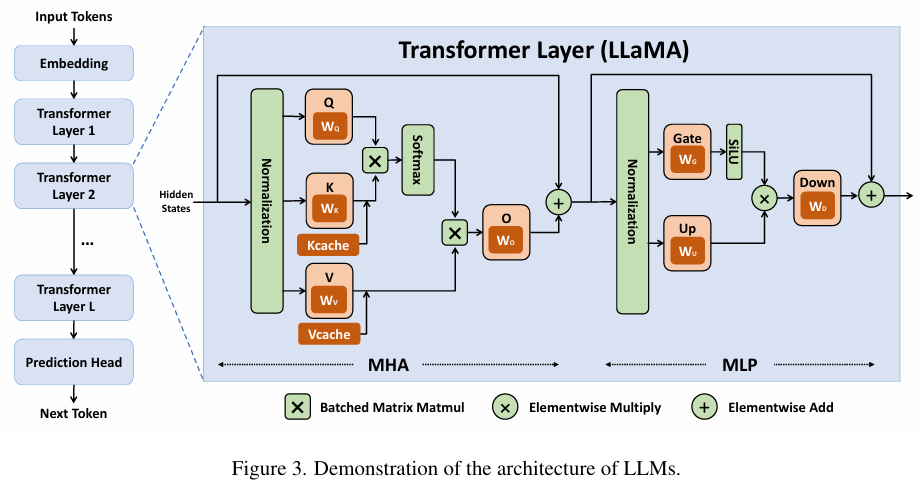
现阶段大语言模型(LLM)普遍采用的Transformer decoder架构,包括embedding layer、多层Transformer和prediction head。embedding将输入tokens转化为hidden states,Transformer层通过Masked Multi-Head Attention(MHA)和多层感知机(MLP)模块处理hidden states,最终由prediction head生成下一个token。
推理过程分为两阶段:Prefill Stage和Decode Stage。Prefill Stage以prompt序列为输入,生成每个Transformer层的Key-Value Cache(KV cache),每个 Transformer 层都配备了自己独有的 KV 缓存,用于存储关键信息,为Decode Stage的后续token生成奠定基础。
1.1.1 Prefill Stage
-
输入:Prompt序列 $(X_{\text{pre}} \in \mathbb{R}^{n \times d})$ (d是隐藏层大小,n是prompt序列长度)
-
生成 KV cache:
$$ Q_{\text{pre}} = X_{\text{pre}} \cdot W_q, \quad K_{\text{pre}} = X_{\text{pre}} \cdot W_k, \quad V_{\text{pre}} = X_{\text{pre}} \cdot W_v $$
其中 $K_{\text{pre}}, V_{\text{pre}}$ 存储到 KV cache。
- MHA计算:
$$ O_{\text{pre}} = \text{softmax}\left(\frac{Q_{\text{pre}} \cdot K_{\text{pre}}^T}{\sqrt{d}}\right) \cdot V_{\text{pre}} \cdot W_o + X_{\text{pre}} $$
这里的权重$W_q$, $W_k$, $W_v$, $W_o$都是模型中储存的信息,由训练阶段得来
输出 $O_{\text{pre}} \in \mathbb{R}^{n \times d}$ 将被传给MLP
1.1.2 Decode Stage
-
输入:当前token $(X_{\text{dec}} \in \mathbb{R}^{1 \times d})$ 和之前生成的 KV cache $(K_{\text{cache}}, V_{\text{cache}})$
-
KV cache更新:
$$ Q_{\text{dec}} = X_{\text{dec}} \cdot W_q, \quad K_{\text{cat}} = [K_{\text{cache}}, X_{\text{dec}} \cdot W_k], \quad V_{\text{cat}} = [V_{\text{cache}}, X_{\text{dec}} \cdot W_v] $$
- MHA计算:
$$ O_{\text{dec}} = \text{softmax}\left(\frac{Q_{\text{dec}} \cdot K_{\text{cat}}^T}{\sqrt{d}}\right) \cdot V_{\text{cat}} \cdot W_o + X_{\text{dec}} $$
输出 $O_{\text{dec}} \in \mathbb{R}^{1 \times d}$ 将被传给MLP,最后一个 Transformer 层的输出被发送到最后的预测层,以预测下一个 token。
1.2 Roofline Model
评估LLM在特定硬件上的效率需要同时考虑硬件和模型特性。
如果某一层计算量很大,但内存访问较少,则称为计算瓶颈(computation bottleneck)。在这种情况下,内存访问单元会处于空闲状态。相反,如果某一层需要大量的内存访问,但计算需求较少,则称为内存瓶颈(memory bottleneck)。在这种情况下,计算单元会处于未充分利用的状态。通过Roofline模型,我们可以清楚地区分这两种情况,并为不同场景提供性能上限的理论估计。
使用Roofline模型过程分为两步:
1.2.1 Plot the Roofline
-
确定硬件的峰值计算性能(OPS)和峰值内存带宽(bytes/s)
-
绘制:
- y轴为理论性能(OPS),x轴为计算强度(OPs/byte)
- 绘制一条水平线表示硬件的计算性能上限(Compute Roofline)
- 从原点绘制一条斜线,斜率为内存带宽(Memory Roofline)
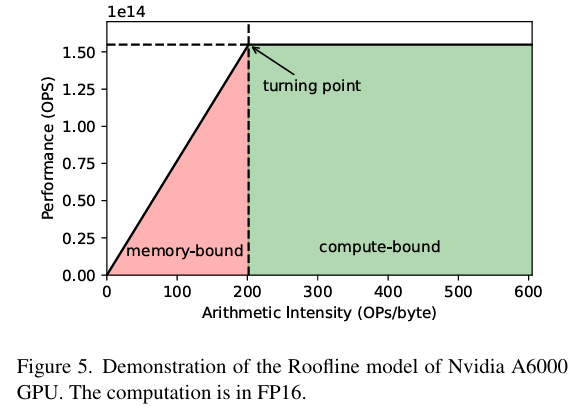
带宽约束(红色区域):当模型的计算强度低于计算平台的计算强度上限(如A此处6000的200)时,模型会落入"Roofline"区间,每次内存访问所需的计算量较少,即使达到 peak bandwidth,计算资源仍未完全利用。在这种情况下,可以通过优化方法如quantization、kernel fusion和增加batch size来减少内存开销。此时模型的理论性能取决于两个因素:计算平台的带宽上限(即房檐斜率)和模型自身的计算强度。典型的带宽受限操作包括elementwise运算(如activation、dropout)和规约运算(如sum、softmax、batch normalization、layer normalization)。
计算约束(绿色区域):在这种情况下,模型需要较少的内存访问来完成大量计算,HBM访存时间的影响相对较小,这说明受限于计算性能,部分内存资源可能未被利用。即使模型的计算强度继续提高,其理论性能也会被计算平台的最大算力所限制。具有较大内维数的矩阵乘法和多通道卷积运算通常属于这种情况。优化策略包括启用low-bit computation以提高计算效率。
[!NOTE]
Prefill阶段通常是compute-bound,因为需要计算大量矩阵乘法
但在以下情况可能变为memory-bound:
- batch size较小时
- 序列长度较短时
- GPU显存带宽较低时
- 模型较小时
Decode阶段通常是memory-bound,因为需要频繁访问KV cache且计算量相对较小(只处理一个token)
但在以下情况可能变为compute-bound:
- batch size较大时
- GPU计算能力较弱时
- 模型较大时
1.2.2 Analyze performance for layers
- 评估每层的性能
- 计算每层的操作数(OPs)和内存数据量(bytes)
- 计算强度 $\text{Arithmetic Intensity} = \frac{\text{OPs}}{\text{bytes}}$
- 根据计算强度的x轴位置,确定每层的理论性能上限
- 判断当前层是 memory-bound 还是 compute-bound,从而指导后续优化
以下为一组具体数据示例:
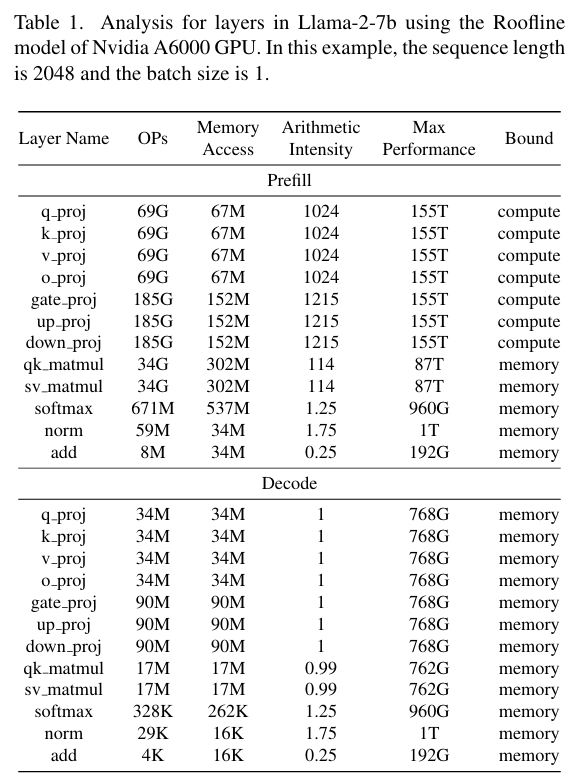
我们可以发现:
- 在Prefill Stage,大多数计算是compute-bound,性能较高。
- 在Decode Stage,所有计算是memory-bound,性能远低于GPU计算单元的理论上限。
由于Prefill Stage只执行一次,而Decode Stage会多次运行以生成连续输出,因此针对Decode Stage的memory-bound特性进行优化对于提升大模型推理性能至关重要。
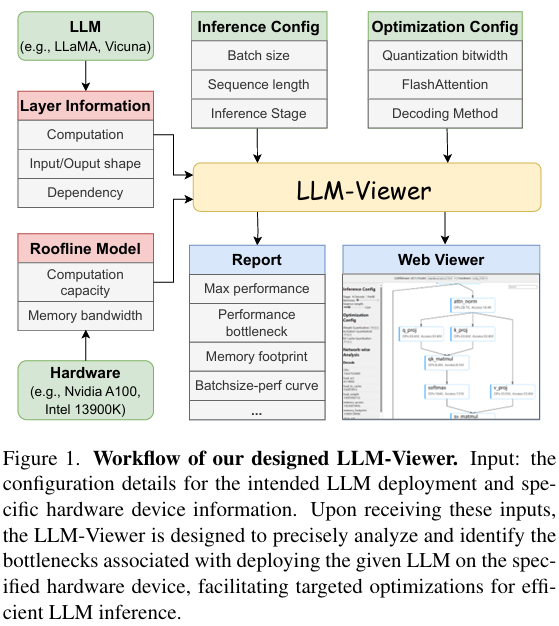
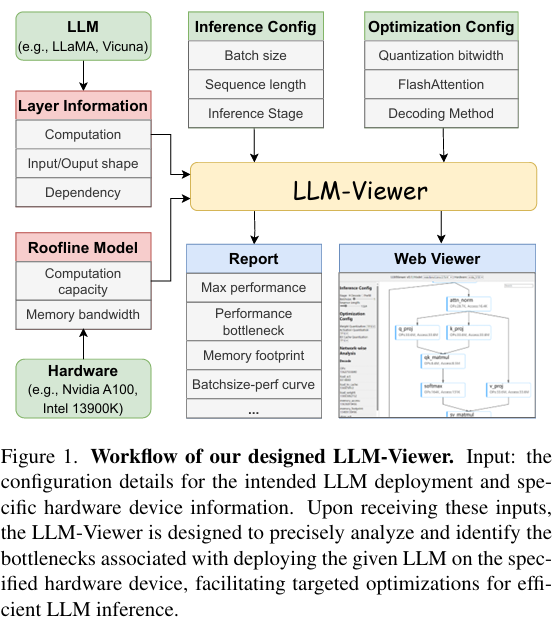
1.3 LLM-Viewer
作者开发了一个工具用以支持对各种硬件平台上的 LLM 性能和效率进行分析吗,其工作流如下图:
2 Model Compression
该部分作者回顾了 Model Compression 的概念,探讨了几种常见的神经网络压缩技术,包括但不限于 quantization、pruning、knowledge distillation 和 low-rank factorization。在每个子部分中,作者利用 LLM-Viewer 推理性能进行了分析,并基于分析提出了优化建议。虽然量化中必然存在一定程度的精度损失,但经过设计的量化技术可以实现效果显著的模型压缩,同时尽可能最小地影响准确性。
LLM 背景下的量化主要可分为两个方向:Quantization for Compressing Pre-trained LLMs and Quantization for Parameter-Efficient Fine-Tuning (Q-PEFT)。第一类又可进一步分为两种子类:Quantization-Aware Training (QAT) and Post-Training Quantization (PTQ)。QAT在模型训练或对预训练模型的微调/重训练过程中部署量化,从训练阶段开始量化模型;**PTQ **在模型训练完成后应用量化,无需重新训练,是一种更为直接的模型压缩方法。
2.1 Quantization
2.1.1 A Use Case of LLM-Viewer: Roofline Analysis for Quantization
在 LLM 中,张量由权重和activations组成,activations包括temporary activations(例如,每个transformer 层的 inputs 都保存在内存中,直到执行residual addition)和 KV cache。
主要从computation, memory consumption和memory access三个角度来分析量化的效果。
2.1.1.1 Computation
硬件在处理具有较小位宽的数据时通常性能更好。NVIDIA 的 A6000 GPU 对于 INT8 的执行速度是 FP16 的两倍,分别为 310 TOP/s 和 155 TOP/s。体现在Roofline model上即为:
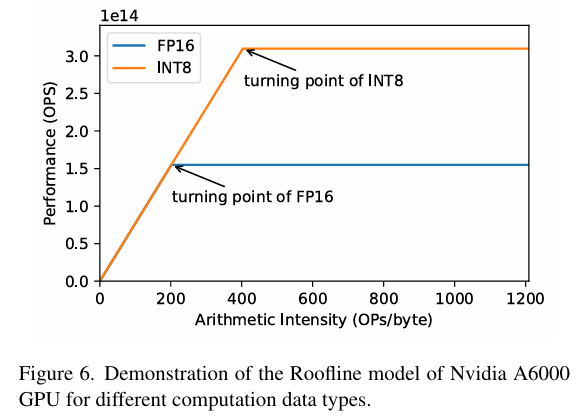
可以这么理解:单位运算内所需的访存下降了一半(OPs/byte中byte变为原来的1/2,x坐标变为原来的两倍,斜率不变,理论性能变为原来的两倍)
但要注意,想要充分利用硬件的INT8计算能力,输入的所有操作数(包括权重和激活值)都必须是INT8格式,如果只把权重量化为INT8,而激活值保持FP16,则无法完全利用INT8的计算能力(无法达到理论最佳性能),在这种情况下,INT8权重反而需要转换回FP16才能与FP16激活值进行计算;此外如果量化后的权重或激活的位宽(如 INT4)不受硬件支持,也必须将其转换到更高的位宽(如 INT8 或 FP16)来进行计算。例如,NVIDIA H100 GPU 不支持原生 INT4 运算,因此量化到 INT4 的数据必须先转为 INT8 或 FP16。
2.1.1.2 Memory Consumption
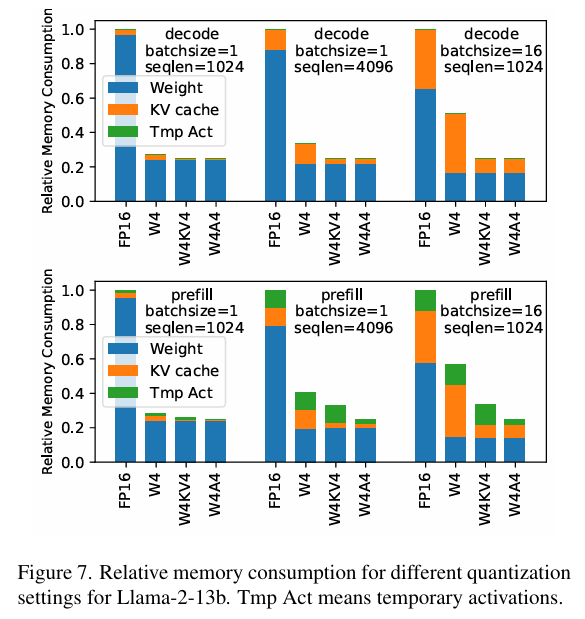
图中W4 表示将权重量化为 4 bits,同时保持 FP16 格式的activations;W4A4 表示权重和activations都量化为 4 bits;W4KV4 表示权重和 KV Cache被量化为 4 bits,而temporary activations保持 FP16
主要发现:
- Temporary activations的内存使用较低,尤其是在 decode 阶段,因其生命周期短,使用后内存可立即释放
- KV cache 的内存分配在生成完整答案前无法释放,因为需要多次decode;且其内存消耗随 batch size 和输入序列长度增加而上升,因需要存储更多的 key-value (KV) 对
2.1.1.3 Memory Access
在 LLM 中量化张量可以显著减少内存访问,单位运算内所需的访存下降一半(理论最佳情况)。量化后会出现三种可能的情况:
-
量化前后都是memory-bound
-
量化是memory-bound,量化后变compute-bound
-
量化前后都是compute-bound
前两者都会因为降低了数据Memory Access的压力而得到理论情况下的性能提升,第三种情况则几乎没有性能提升(可以这么理解,本身情况就是compute-bound的话,紧张的是算力单元,而量化缓解的是内存压力。进一步地也能解释理论情况下为什么不会有量化是compute-bound,量化后变memory-bound的情况)
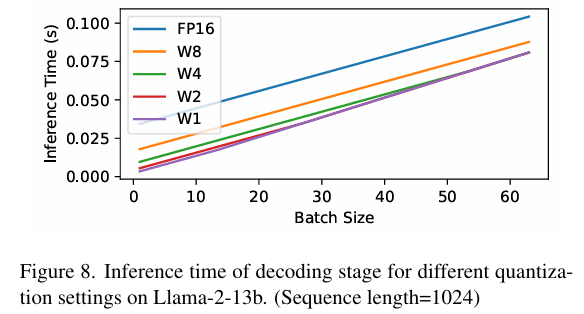
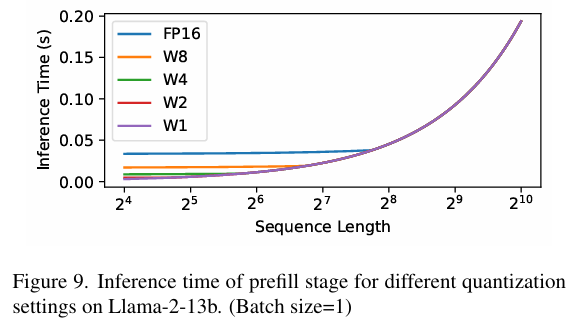
测试结果也可以证明这点:
- 当 batch size 较小时,网络层为 memory-bound,量化可以提升性能并减少推理时间
- 当 batch size 较大时,网络变为 compute-bound,进一步量化权重(如 4-bit 到 2-bit 或 1-bit)对性能提升无明显效果
- 在 prefill 阶段,若 sequence length 较小,网络为 memory-bound,量化能减少内存访问需求并提升性能;随着 sequence length 增加,prefill stage 逐渐变为 compute-bound,量化对性能的提升作用减弱
2.1.2 Quantization for Compressing Pre-trained LLMs
2.1.2.1 Quantization-Aware Training(QAT)
量化过程集成到LLM的训练中,使它们能够适应低精度表示,从而减少精度损失。
- LLM-QAT(Liu et al., 2023),通过data-free distillation解决了数据获取问题,利用预训练模型的输出避免了大量数据收集的需求;还将量化扩展到KV Cache,从而提高了吞吐量并支持了更长的序列
- 为了实现更低比特的量化(如低于2位),Kim等人(Kim et al., 2023)提出了基于 token confidence的自适应knowledge distillation方法: Token-Scaled Logit Distil lation (TSLD),用于三值量化(ternary QAT)
- Shang等人(Shang et al., 2023)则提出了部分二值化矩阵(PB-LLM),通过保持关键权重在较高精度中,确保了高度量化的LLM在推理能力上的表现,同时通过优化scaling factors最小化quantization error
2.1.2.2 Post-Training Quantization(PTQ)
PTQ 是在 LLM 训练后进行的量化技术,主要目的是减少模型存储需求和计算复杂度。与 QAT 相比,PTQ 更适合较大的模型,因为 QAT 在处理包含数十亿参数的 LLM 时训练成本过高。其优势在于:无需改变模型架构,无需重新训练,操作简单高效;劣势在于量化过程会导致一定的精度损失。
- LUT GEMM: 通过权重量化和BCQ格式优化矩阵乘法,提高计算效率
- LLM.int8(): 使用8-bit量化;通过向量级量化和混合精度分解保持精度;可支持1750亿参数模型的推理;GPU内存使用减半
- ZeroQuant: 结合 hardware-friendly的量化方案;使用layer-by-layer knowledge distillation;将权重和激活都优化到INT8
- GPTQ: 基于approximate second-order information的逐层量化技术;可将权重压缩到3-4 bits且精度损失小
- AWQ: 保护关键权重以减少量化误差;关注较大激活幅度的权重通道;使用per-channel scaling优化量化
- OWQ: 分析激活异常值如何放大量化误差,使用混合精度方案为受异常值影响的权重分配更高的精度
- SpQR: 隔离异常权重以便以更高的精度存储,同时将余数压缩为 3-4 位,从而实现更高效的压缩和近乎无损的性能
- QuantEase: 使用coordinate descent优化网络权重,提高量化效率
- QuIP: 通过利用adaptive rounding和efficient pre/post-processing techniques(例如随机正交矩阵乘法)来量化低于 2 位的权重,以保持量化有效性
- Norm Tweaking: 提出了一种将量化激活分布与浮点激活分布对齐的策略,通过细致的校准过程和channel-wise distance约束更新规范化层权重,从而提高 LLM 的准确性
- PB-LLM: 将binarization引入 LLM 量化,将权重量化推至 2 位以下
- SmoothQuant: 专注于通过使用per-channel scaling变换来平滑激活幅度来量化激活,从而克服由异常值引起的问题
- RPTQ: 通过clustering channels,reordering channels和integrating layer normalization来解决激活量化中的不均匀范围和异常值,以最大限度地减少开销
- OliVe and Outlier Suppression+: 引入outlier-victim pair策略,以较低的硬件开销解决局部异常值;Outlier Suppression+ 则专注于通过channel-wise shifting and scaling来平衡异常值分布
- ZeroQuant-FP: 探索浮点量化,发现激活的 FP8 和权重的 FP4 优于传统的 INT8 和 INT4 格式。它通过标准化scaling factors并将其限制为single compute group来确保一致性
- FPTQ: 采用layerwise策略和offline logarithmic activation equalization来优化难以量化的层
- KV Cache Quantization: 随着token长度的增加,KV Cache量化已成为内存优化的关键
- KIVI (Liu et al., 2024b) 将 KV Cache量化推至 2 bits
- WKVQuant (Yue et al., 2024) 联合优化权重和 KV Cache,实现与 W4KV4 量化类似的性能
2.1.3 Quantization for Parameter Efficient Fine Tuning (Q-PEFT)
Parameter-Efficient Fine-Tuning (PEFT) 旨在通过减少可调参数数量,同时保持较高的模型性能。其中最有名的方法之一就是 Low-Rank Adaptation (LoRA),一种流行的PEFT方法,通过将adapter weights分解成两个低秩矩阵来减少可调参数的数量。该方法能够在参数数量大幅减少的情况下,获得与full fine-tuning相当的性能。
此外,Quanti zation for Parameter-Efficient Fine-Tuning (Q-PEFT) 也逐渐兴起,这是一种将量化方法集成到微调过程中的新范式,特别适用于大型模型的高效优化,该领域的主要方法包括:
-
PEQA:使用双阶段过程,首先将参数矩阵量化为低比特整数,然后在第二阶段对下游任务进行微调
-
DFT:结合Lion优化器,量化模型状态,并为量化权重提供gradient flow和参数更新方案
-
QLORA:最多支持4 bits量化,适用于低比特量化的PEFT方法;局限性:4 bits量化会影响性能,而更低比特的量化(如2比特)通常会导致精度下降,为了解决这类问题,一些研究开始涉足Q-PEFT 领域并得到了以下一些进展:
-
LQ-LoRA:采用迭代算法,将预训练的每个矩阵分解为高精度的低秩组件和量化组件。低秩组件在微调过程中更新,而量化部分保持不变。这种方法允许动态配置量化参数,如bit-width和block size
-
Loft-Q:量化LLM并为LoRA微调建立合适的低秩初始化,改进了下游任务中的泛化能力
-
QA-LoRA:将LLM的权重量化为低比特整数以进行高效微调,在保持轻量级微调模型的同时,最大限度地减少了精度损失
-
这些方法对于平衡内存效率与模型性能至关重要,推动了低比特量化和参数高效微调在大型模型中的应用。
2.2 Pruning
Pruning 是一种通过识别并移除不必要或冗余的模型参数来压缩 LLM 的常用技术。通过合理的 Pruning,可以在不显著降低性能的前提下优化模型。其方法主要有两类:
2.2.1 Unstructured pruning
Unstructured pruning 通过选择性地去除模型中的权重或神经元来实现模型稀疏化,虽然能保证较高的模型准确性,但会导致权重分布的不规则性,从而需要专门的处理或软件层面的优化。
- SparseGPT 是一种专门针对LLMs的单次剪枝方法,它将剪枝问题重新定义为一系列稀疏回归问题,通过新开发的求解器高效解决。SparseGPT 能够在几小时内通过单GPU处理包含1750亿参数的模型,并在不显著牺牲准确性的情况下实现50-60%的稀疏化,无需微调
- Wanda 通过评估每个权重的magnitude和对应输入的norm来提高计算效率,进一步可以降低SparseGPT中的重构成本
- Outlier weighed layerwise sparsity (owl) 提出使用非均匀的层次稀疏比例,重点处理异常值较多的层,从而提高剪枝效果
- Flash-LLM 结合考虑硬件支持,提出了一种无结构稀疏矩阵乘 方法,通过稀疏加载和密集计算,优化了GPU Tensor Core对unstructured sparsity的支持
2.2.2 Structured pruning
Structured pruning 通过去除整个神经元或层,生成更加简洁、规则的网络结构。尽管这种方法在硬件兼容性上更具优势,但由于去除的组件可能较大且potentially more critical,它可能对模型性能产生较大的影响
- LLM-Pruner 是结构化剪枝的一个开创性方法,采用one-shot pruning技术,基于 first-order 和 estimated Hessian data,并通过LoRA进行后续微调以恢复权重。该方法显著减少了计算和内存需求,同时保持了LLM的基本结构
- Sheared Llama 提出了一种结合有针对性的结构化剪枝和动态批量加载算法的解决方案。首先,它通过分析预训练模型的配置,精确剪枝源模型到目标架构。然后,通过动态批量加载算法提高训练效率,调整不同领域的训练数据比例
- Compresso 建立了一个协同学习框架,LLM与 resource-efficient的剪枝算法协同工作,能够将Llama-7B修剪至5.4B,同时保持原始性能
2.3 Knowledge Distillation
Knowledge distillation 是一种将大模型(“教师”模型)的能力转移到小模型(“学生”模型)中的技术,使得小模型能够以较低的计算资源,完成与大模型相似的任务。主要分为两类:
2.3.1 White-Box Knowledge Distillation
在白盒蒸馏中,教师模型的架构和权重是完全可访问的,允许学生模型学习教师的输出和内部表示。
- MiniLLM 批评了传统的知识蒸馏objectives,并提倡在生成任务中使用反向 Kullback-Leibler divergence,以提高学生模型的响应质量。它还引入了single-step regularization、teacher-mixed sampling和length normalization等技术来增强训练
- GKD 提供了一种更简单、更稳定的方法,使用教师指导的序列训练学生并避免反向传播
- Homotopic distillation 通过降低神经元复杂性将学生模型的预测与教师对齐
- AD-KD 使用integrated gradients将token级attributional knowledge从老师转移到学生,使学生能够模仿老师的推理
2.3.2 Black-Box Knowledge Distillation
与白盒蒸馏不同,黑盒蒸馏不需要访问教师模型的内部信息,而是通过模仿教师模型的输出行为进行学习。学生模型仅通过教师模型生成的(输入,输出)对进行学习,不涉及教师模型的内部操作。
- Multitask-ICT 提出了结合上下文学习与语言建模的蒸馏方法,旨在让学生模型在理解上下文示例的同时,获得特定任务所需的知识
- LaMini-LM 使用 258 万个指令,通过 GPT-3.5 Turbo 生成回应,并以此为基础对学生模型进行微调
- PromptMix 采用基于prompting的两步法,生成带标签的文本分类样例, borderline 样例能够促进教师模型向学生模型的知识传递
- Lion 提出了一个对抗性蒸馏框架,通过让教师模型识别“困难”指令并生成新的“困难”指令,形成一个动态的三步对抗循环
黑盒蒸馏也被认为是将链式推理(CoT)提示从大模型转移到小模型的有效工具
- SCOTT 使用contrastive decoding 和 counterfactual reasoning objective,提高了 CoT rationales的忠实度
- Distilling step-by-step 提出了新的训练方法,通过将 LLM rationales作为额外训练材料,在多任务框架下减少数据需求
- Symbolic CoT distillation 通过获取教师模型的 CoT rationales并训练学生模型预测 rationale 和 label
- Dialogue chain of-thought distillation 通过将 LLMs 作为非一致教师,通过alignment filters提炼出有价值的rationales
2.4 Factorization
低秩矩阵分解(Low-rank matrix decomposition)是一种常用的深度神经网络(DNNs)压缩技术,近年来在科学计算和机器学习领域引起了广泛关注。通过低秩方法压缩和加速大规模神经网络成为研究的重点,推动了低秩分解策略的创新与发展。
- ASVD (Activation-aware Singular Value Decomposition): 首个应用于LLM压缩的分解技术,通过调整权重矩阵来处理激活异常值,并采用迭代校准来优化不同层的分解
- LASER (LAyer-SElective Rank reduction): 通过选择性地移除权重矩阵的高阶分量来提升LLM性能
- TensorGPT: 使用Tensor-Train Decomposition (TTD)技术压缩LLM的嵌入层,以低秩张量格式存储大型嵌入,从而减少参数数量
3 Algorithmic Methods for Fast Decoding
LLM 在 text generation 任务中表现出色,但随着模型参数增大,decode过程变 memory-bound,硬件利用率低,导致high-latency。
作者在文章中主要介绍了两个优化方向:1. 针对单个 token 解码:如何使用最少的模型参数 2. 针对单次前向传播:如何解码最多的 tokens
3.1 Minimum Parameter Used Per Token Decoded
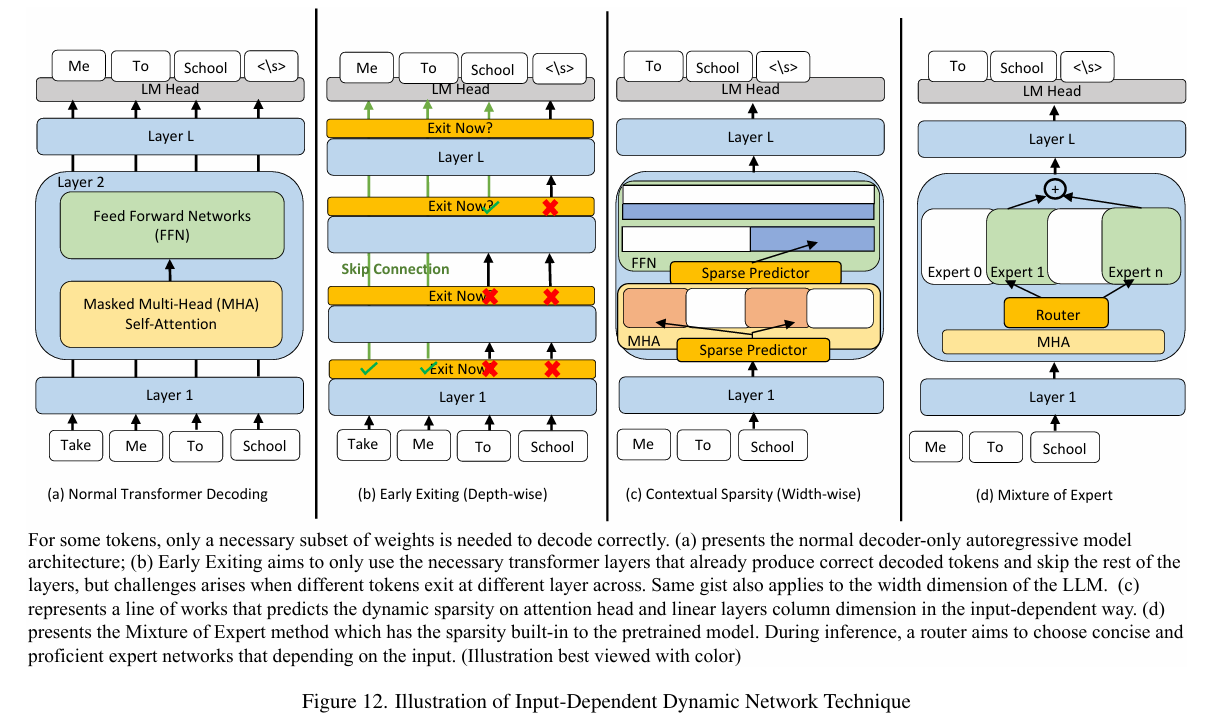
尽管LLM往往具有大量参数,但并非所有参数都是必要的。通过仅选择一些必要参数的子集来生成token同时仍然保持decoding的准确性,就可以降低推理延迟。接下来将分别展开介绍三种input-dependent dynamic weights dropping scheme:Early Exiting, Contextual Sparsity以及Mixture-of-Expert Models(MoE)。
3.1.1 Early Exiting
Early Exiting,也叫 layer skipping,是一种机制,当模型判断进一步的计算对达成足够的准确度已经没有必要时,可以跳过后续层的计算,从而减少计算成本。
这一技术在**仅编码器架构(encoder-only architectures)**中发展比较成熟,比如 BERT。对于这种架构,Early Exiting更容易实现,因为它们在推理时将输入序列作为整体处理,各个 token 之间没有像解码器那样的依赖关系。
在**仅解码器架构(decoder-only architectures)**模型中,每个 token 的输出都依赖于之前生成的所有 token,因为这些模型使用的是自回归(autoregressive)解码方式。这种序列依赖性为早退出引入了额外的复杂性。所以为了让Early Exiting在解码器中有效,必须确保整个序列的consistency和quality,而不仅仅是单个 token 的正确性。如果中间层过早退出,可能导致生成的序列缺乏连贯性。
为了解决这个问题,有研究者观察到,对于某些 token,其隐藏状态(hidden states)在中间层时会趋于饱和(saturate)。
[!NOTE]
这里饱和表示某些 token 的隐藏状态在中间层已经稳定下来,不再发生明显变化。这意味着这些 token 的特征基本已经被模型充分学习和表达,即使继续经过更多层的处理,其输出结果也不会有显著变化。
这一观察结果为解码器早退出方法的成功奠定了基础。
进一步的,针对于decoder-only的Early Exiting通用办法出现了,如下图(b)所示。在前向传播过程中,每一层之后都会应用一个内部的 confidence function(置信度函数),该函数通常是一个固定的度量标准或一个具有少量层数的 MLP。这个函数根据 hidden states计算 confidence score(置信度分数),用于评估当前层是否已经趋于饱和的可能性。然后根据巧妙设计的标准使用该分数来决定是否提前退出。如果选择退出,则通过LM Head生成下一个预测词的概率分布。
由于后续相关工作具有高度的相似性,作者进一步讨论了Early Exiting实现中的四个主要挑战。
3.1.1.1 Modeling the Confidence of Saturation
CALM [Schuster et al., 2022] 研究了三种不同的方法来计算用于退出的 confidence score:第一种是 softmax response,即 softmax 后的最大值,或者是 softmax 后的前二最大值的差值;第二种是隐藏状态的饱和度,即当前层的隐藏状态与最后一层的隐藏状态之间的 cosine similarity(余弦相似度);第三种是在每一层插入一个线性分类器,这个线性分类器通过输入隐藏状态,使用 cross-entropy loss(交叉熵损失)来训练,使其输出与当前层的 top-1 token(最高概率的词)是否与完整模型预测的 top-1 token 一致进行对齐。
实验表明,尽管线性分类器方法不是最准确的预测方式,但它在生成分数时的计算 FLOPs 开销与预测精度之间达到了最佳权衡。
基于 CALM 的方法,[Bae et al., 2023] 观察到,如果持续从浅层退出,会导致异常长的生成序列长度。同时,每层都计算置信分数会带来较高的开销,从而降低早退出的效益。因此,Bae 等人提出了一种优化方案:只设置两种退出选择——要么从所谓的 “shallow module”(浅层模块)或一组浅层中退出,要么直接运行完整模型(即 “deep module” 深层模块)。这种设计显著减少了模型内部所需的分类器数量,使其在某些任务上实现了比 CALM 更高的加速效果,最高可达 2 倍。
ConsistentEE [Zeng et al., 2023] 提出了一种不同的方法来预测退出时机。它采用了一个 RL policy network,该网络通过每层输出的分类头进行迭代训练。策略网络的目标是平衡效率(早退出的层会获得奖励)和精度(奖励函数包含一个基于早退出输出的 CE loss 项)的优化。这种方法为早退出提供了一种新思路。
3.1.1.2 Early Exit Criteria
CALM 提出了一种distribution-free calibration technique(不依赖分布的校准技术),通过固定序列测试来输出合适的阈值。该阈值呈指数下降,从而允许在序列后期对 token 进行更激进的退出决策。
Bae 等人观察到置信度标准的模式类似 Beta Distribution,他们利用实时生成的数据通过最大似然估计更新 Beta 分布模型,并使用该概率模型来指导退出决策。
ConsistentEE 则绕过了这一问题,直接通过策略网络输出退出决策。
3.1.1.3 Hidden States Propagation
根据以上内容应用Early Exit机制时我们会发现有一个麻烦,比如上图(b)中,token “school” 的位置比前面的 token 退出的更晚。但是最后一个自注意力层并没有之前那些已提前退出的 token 的 KV-Pair。
为此,“Hidden States Propagation” 技术诞生:例如,token “me” 在退出层 $l_{1}$ 的隐藏状态会被存储,当后续的 token “school” 到达更深的层 $l_{2}$ 时,“me” 的隐藏状态会被复制到从 $l_{1}$ 到 $l_{2}$ 之间的所有层,并在复制的隐藏状态上计算 key-value 对。
后续的研究发现,Hidden States Propagation会导致性能下降。由于 LLM 推理过程主要受内存加载影响,而计算资源则相对”廉价“,有学者则提出直接实时重新计算后续隐藏状态的方法;此外也有学者提出在早退出流的同时并行运行完整的大模型,从而高效地并行计算缺失的 kv cache;还有学者对 Transformer 架构中使用线性网络进行跨层跳跃进行了系统研究,并发现可以通过添加线性层,在低内存和计算成本下有效弥合直接复制和重新计算隐藏状态之间的性能差距;SkipDecode则采用了一种更激进的方法,优先考虑推理加速,并放宽了性能保持的目标。通过利用以下观察:同一序列中出现较晚的 token 平均需要更少的层数来正确解码(后续 token 的上下文依赖性较强,而这种依赖的信息已经在前面的计算中生成和传递。换句话说,解码的任务变得更简单了),它完全跳过了Hidden States Propagation,通过强制设计,限制序列中每个 token 所需的最大层数,使得这些层的深度对于序列中的位置单调递减(即越靠后的 token,使用的最大层数越少。比如,第一个 token 使用 12 层计算,第二个 token 只使用 10 层,最后一个 token 可能只使用 6 层)。此外,SkipDecode 引入了固定退出点,以优化批量早退出的效率。
3.1.1.4 Output Classifier Training
当从中间层退出时,中间隐藏状态需要通过一个 output classifier head 来预测下一个 token 的概率分布。这个输出分类器可以是共享的,也可以是每层独立的。这些分类器通常通过训练来更好地适应Early Exit。
有学者提出使用所有层的平均 CE loss(交叉熵损失)作为分类器的训练损失;有学者则采用了一种加权平均方法,其中权重随着层数的增加而增加,从而赋予较深层更多的"contribution";有学者提出了一种动态知识蒸馏损失,该方法动态地为 “shallow module” 分配来自 “deep module” 合适的隐藏状态;有学者发现在 使用相同损失 联合训练所有模型时会存在conflicting gradient问题,他们提出可以通过添加额外的参数和迭代训练来缓解这些问题;还有学者研究了系统层面的优化技术,以在 3D parallelism(三维并行)设置下高效运行 LLM 的Early Exit机制。
3.1.2 Contextual Sparsity
如上图(b),Early Exit旨在纵向“选择”参数;自然而然也有在横向–宽度维度上利用动态稀疏性的技巧。
Deja Vu 对LLM宽度维度上的动态稀疏性进行了全面研究,发现 contextual sparsity 可以高达80%,这意味着大多数权重都可以被省略的同时,仍能基本上保持原始模型的性能。然而选择的权重是动态且随不同的token序列有区别的。学者团队将此问题表述为一个nearly neighbor search problem(近邻搜索问题),即对于来自前一嵌入层的给定隐藏状态,如何找到与这些tokens最相似的注意力头和MLP columns。为了节省计算,论文建议在LLM的 MHA 和 FFN 之前训练一个小型MLP网络作为稀疏预测器,如上图(c)所示。通过仅使用一部分权重并减少内存IO开销,Deja Vu实现了超过2倍速度的提升。
在Deja Vu的基础上,PowerInfer 将 contextual sparsity 应用于异构设备(CPU和GPU)的推理。PowerInfer发现,在 input-independent setting中有很大部分权重被大量使用和激活—因此将这些存储在GPU,而其他(使用较少的权重)则存储在CPU内存中。然后,为了找到给定输入token要使用的权重,它训练了一个比Deja Vu更小的稀疏预测器。它初始化稀疏预测器以具有动态结构迭代地训练和修改自身参数。为了更好地在异构环境中进行推理,它又引入了一种新颖的 memory placement 方案,并实现了一个基于向量的稀疏计算库。
MatFormer 则研究了在不同硬件能力的各种异构设备上部署LLM的问题。他们仅在占总权重60%的FFN上添加了动态结构。模型经过特殊训练,以便在推理过程中在 row dimension 上基于目标硬件属性对MLP层进行采样,以提供具有合理性能的各种尺寸的模型。为了多样化模型尺寸选择,它采用了Mix’n’Match方法,为不同层选择不同的设置,以便组合后能提供更具变化的模型尺寸。
3.1.3 Mixture-of-Expert Models
语言模型,特别是基于Transformer架构的模型,在训练数据集规模扩大时表现出强劲的幂律增长。然而,尽管参数数量的增加带来了显著的性能提升,但也导致模型训练和推理效率低下。**Mixture of Experts(MoE)**技术为此而生,它能够有效地将模型的参数数量与训练和推理所需的计算FLOPs解耦,从而在特定条件下显著提升效率。此外,MoE被证明能够有效扩展语言模型的规模并提升其性能,而无需担心推理时计算量的增加。
如上图(d)所示,专家网络被插入到Transformer架构中以替代FFN层。同时,在MHA和专家网络之间引入了一个gating function,旨在为给定的输入token选择最合适的专家或专家组合。关于MoE的扩展性、路由算法、训练技术等的深入分析和讨论,可参考Fedus等人的《Sparse Expert Models》综述。
[!NOTE]
尽管MoE和Contextual Sparsity都依赖于输入来决定sparse structure,但后者作用于pre-trained dense language models并利用密集神经网络中的稀疏性,而前者则从一开始就训练为稀疏模型。
近年来,MoE技术取得了显著的成功。例如,SparseMixer 在BERT模型的训练和推理中分别实现了89%和98%的加速;ST-MoE 将MoE引入 encoder-decoder 模型,成为许多推理和生成任务的SOTA。ST-MoE在训练和推理中分别使用了20倍和40倍更少的FLOPs,性能超过了540B的PaLM;还有学者利用MoE,使得Mixtral8x7B在推理过程中仅活跃使用13B参数,而性能与Llama2-70B在各种评估基准上相当。
此外还有多种优化MoE模型推理的尝试。例如,有学者构建了一个用于MoE模型的高效编译器library RECOMPILE,可以根据不同batch size进行动态重编译和优化;有学者将ZeRO分布式推理方法扩展到MoE模型;有学者对专家网络架构进行了Neural Architecture Search(NAS);还有学者将大型MoE语言模型部署到边缘设备并做了优化,发现MoE模型中某些神经元的使用频率远高于其他神经元。
3.2 Maximum Tokens Decoded Per LLM Forward Propagation
降低大模型推理延迟的另一个角度是放宽LLM在autoregressive decoding上的限制,即尝试在一次前向传播中解码出多个token。这里主要介绍了两种办法:1. speculative decoding(推测解码),它引入了一个计算效率更高的draft model(草稿模型),用于生成接下来几个token位置的备选内容,而LLM的任务是评估这些备选内容并输出,而不是逐步生成下一个token。2. Parallel Decoding(并行解码)则是一系列方法用于在一次前向传播中直接解码出多个token。
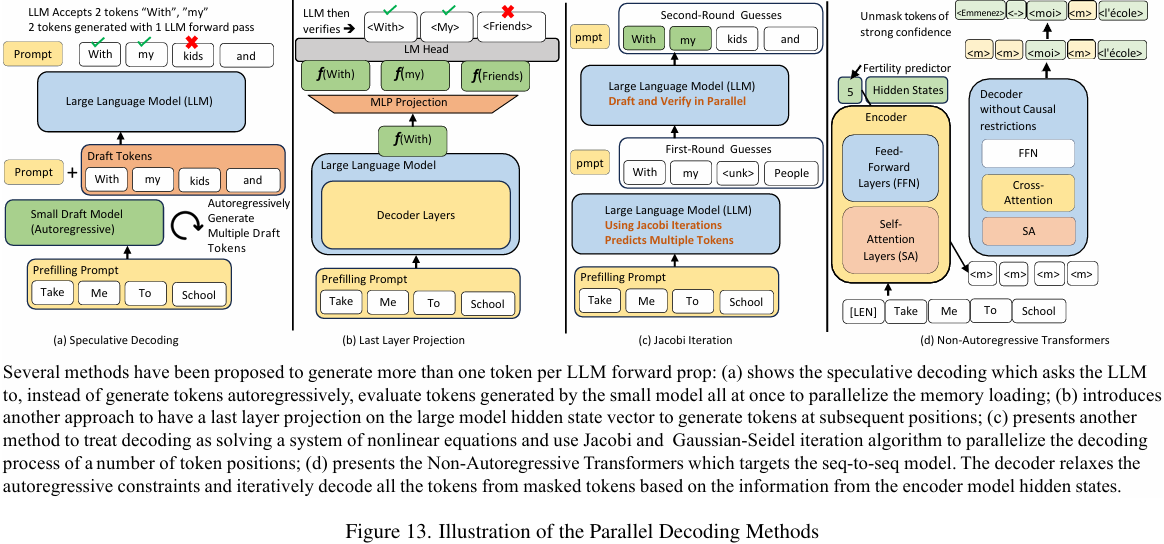
3.2.1 Speculative Decoding
由于memory loading要求高和autoregressive特性,LLM在推理时效率较低。但根据Speculative Decoding with Big Little Decoder,只要对小型模型生成序列中的某些关键token进行修正,规模小得多的模型也能解码出与LLM相同的正确序列。
如上图(a)所示,当让小型模型进行推理并输出draft tokens序列时,模型权重的memory loading压力较小,从而能更好地利用硬件的计算单元。同时为了确保小型模型生成文本的质量,LLM可以周期性地评估和修正来自小型模型的draft tokens。虽然LLM有时需要评估错误的draft tokens,这可能导致消耗的FLOPs比直接autoregressive解码更多,但权重的memory loading在token维度上是并行的,大大减少了内存IO开销。
3.2.1.1 LLM Distribution Preserving
早期在探究Speculative Decoding idea的时候主要有两个大方向:一种是让小模型进行推测并生成draft tokens,直到token解码置信度低于某个阈值。此时,小模型"fall back"到大模型来评估已生成的draft tokens,然后再交回小模型。如果有tokens被拒绝,大模型会要求小模型"roll back"这些错误tokens并重新开始推测,所有解码都采用"greedy"方式。而另一种则是在小模型推测范式的基础上,在LLM拒绝小模型预测的位置上采用一种新提出的resampling技术,这种技术可以确保大小模型组合的预测与大模型的autoregressive生成具有相同的概率分布。后续工作普遍都遵循这种先推测再评估和重采样的范式,以在提高速度的同时保持LLM autoregressive解码的质量。
3.2.1.2 Building a Tree of Draft Tokens
由于LLM的autoregressive特性,每个token都依赖于之前生成的所有token。小模型生成的draft tokens长度通常比较有限,预测更远的token难度会呈指数级增加。比如当小模型输出长度为m的草稿序列,而LLM只接受其中n个token时(n<m),剩余的(m-n)个令牌会被自动丢弃。这导致speculative decoding的加速比较有限。为了改善这种情况主要有两种办法:1. 在batch size方向上提升draft generation,或者让小模型采样多个可能的draft序列以供LLM并行评估(将speculative decoding与discrete optimal transport问题联系起来,让小模型使用topk sampling生成多个draft序列,基于离散最优传输的性质,找到评估和重新采样的最佳方法变成了寻找最佳传输路径);2. 基于多个经过不同训练的小模型构建token tree(他们提出了一种新的树构建算法,通过predefined expanding 和 merging schemes构建备选Tree of Draft Tokens,然后,大模型使用设计过的tree attention并行地验证构建的树,以最大化KV Cache的重用并保持tree-based causal mask),这些模型并行运行并输出多样化但高质量的draft序列。
此外还有工作将speculative decoding应用于edge devices,设计了一个边缘LLM serving引擎,其中较小的draft LLM常驻内存,而较大的LLM则按需加载进行验证。他们实现了 tree-based 并行验证解码器,并针对边缘硬件特点优化了计算流程。
3.2.1.3 Knowledge Distillation and Self-Speculative Decoding
另一种提高 acceptance rate 的方法是提高小型draft LLM与LLM生成分布的对齐能力,这可以通过知识蒸馏的方式在大模型生成的语料上对小模型进行微调来实现。
有学者建立了将 acceptance rate与大小模型间的natural divergence联系起来的数学联系,即最小化散度即最大化接受率。使用Knowledge Distillation可以带来10-45%的延迟优化,而最佳的Knowledge Distillation loss需要根据具体模型来调整;还有学者证明了Knowledge Distillation确实能提升小模型训练效果,另外在云端在线学习环境中,可以利用剩余计算资源持续训练draft model,这带来两个好处:提高接受率降低延迟,以及可以适应不同领域的输入变化;还有学者提出了一种新方法:通过从大模型本身选择性地采样出一个较小的draft 模型,避免了存储单独的draft 模型(利用贝叶斯优化方法,通过跳过预训练LLM的中间层来搜索draft 模型)。此外他们还提出了一种自适应阈值选择技术,专门针对从大模型中采样的draft 模型的decoding过程。
3.2.2 Parallel Decoding
自然而然也有很多工作致力于使LLM能够在没有小模型帮助的情况下直接进行并行解码:
3.2.2.1 Simultaneously Predicting Multiple Future Tokens
这部分工作主要尝试通过单次前向传播来直接预测多个 token。
有学者提出过在最后 hidden states 的输出和 language modeling head 输入之间插入一个 linear projecting layer,使得仅基于当前 token 的最后的 hidden states 就能预测多个未来 token。这项技术主要针对具有 decoder 结构的 sequence-to-sequence 模型;进一步有学者将上述工作扩展到 decoder-only LLM。除了使用 projecting layer 外,还提出了基于 tree-based decoding structure 和相应的 attention mask 设计,以同时提出多个供LLM评估的草稿,见上图(b);还有学者提出在input序列末尾添加称为 “lookahead embeddings” 的虚拟 token。在每一层的前向传播过程中,可以利用之前的prompt tokens 和已解码 token 的信息来并行解码多个连续的未来 token,该工作训练了一个专门服务于这些 lookahead embeddings 的独立嵌入层;还有学者尝试添加了一个轻量级结构 FeatExtrapolator,该结构同时接收之前 token 最后的 hidden states 和实际解码的 token embedding 作为输入,并输出下一层的 hidden states 预测。然后使用 LLM 的 LM head 采样多个 token,用于构建解码树,供 LLM 并行评估。
3.2.2.2 Retrieval of Frequent N-grams
利用 NLP 领域经常出现的 n-grams 来实现在一次前向传递中生成多个未来 token 也是策略之一,主要包括以下几个研究方向:
LLMA 的研究发现生成任务往往会要求 LLM 重复之前上下文中出现的token。基于此他们提出使用已解码的 token 和 prompt 与参考文档进行prefix matching,当发现重复时可直接复制相关token,然后由 LLM 评估这些备选词元是否可以直接使用;接着有学者对 LLMA 进行了扩展,提出先基于 LLM 预训练或微调数据集构建常用短语数据库。在解码过程中,使用之前的上下文作为查询来检索数据库。检索到的候选项被组织成 prefix tree 或 trie 结构供 LLM 进行高效评估;此外还有学者同样采用在 LLM 末端添加额外的 attention layer,使用当前 token 的隐藏状态作为查询向量,对检索到的相关短语进行注意力计算,并基于 attention scores 选择最优短语。
这些方法都致力于通过检索和复用已有文本片段来提高 LLM 的生成效率。
3.2.2.3 Hierarchical Structure In Language
语言往往存在层级结构特征。比如在写作长篇文章时,我们通常会先写出文章的大纲,然后再针对每个子章节分别展开详细论述。基于每个子章节之间在语义上相对独立这一观察结论,有若干研究致力于实现不同子章节的并行生成:
Skeleton-of-Thoughts 提出先让LLM生成文章的简明要点,然后在 batch axis 上收集这些要点,再将它们作为prompt输入LLM,要求模型并行展开对每个要点的论述。这种方法实现了约2倍的加速,但缺点是难以推广到所有文本生成任务;最近,APAR 在这个方向上进行了扩展,他们研究添加了"specific soft tokens",用来明确告知 LLM 生成过程中的层级信息,通过对 LLM 进行指令微调来整合这些特殊tokens,并结合 Medusa 技术,在具有层级结构的文本生成任务上实现了约4倍的加速。
3.2.2.4 Jacobi and Gaussian-Seidel Iterative Algorithms
Accelerating Feedforward Computation via Parallel Nonlinear Equation Solving 这篇文章在 2021 年首次研究使用并行化方法来近似全连接网络和 CNNs 的迭代式和顺序推理结果。研究发现,尽管这个想法看似不可行,但神经网络能够容忍 numerical approximation errors,且神经网络学习到的数据模式在某种程度上具有并行结构,这使得在某些场景下可以实现神经网络顺序推理的并行化。
Jacobi 和 Gaussian-Seidel Algorithms 最初被提出用于解决非线性方程组,后来被证明可以有效地并行化神经网络的顺序推理。有学者将这些算法扩展到机器翻译任务中的 autoregressive decoding 并行化。该工作基于 Non-Autoregressive Transformers 架构,通过 GS-Jacobi algorithms 增强并行解码能力。当解码文本中发现 [EOS] token 时,并行解码过程停止。
同时,Lookahead decoding 将这种方法扩展到了 LLM 后续 tokens 生成的并行化,见上图(c)。除了使用基础的 Jacobi iterative algorithm,它还通过基于检索的算法来复用之前见过的 n-grams 来提升速度。此外,通过在原始 LLM 模型中引入经过设计的 attention mask,可以实现 lookahead 步骤和 LLM 验证步骤的并行化,进一步提高了解码效率。
3.2.2.5 Non-Autoregressive Transformers
Non-Autoregressive Transformers (NAT) 被提出用于改进需要 autoregressive 解码的 sequence-to-sequence 模型,其特点是可以同时并行解码所有输出tokens,见上图(d)。其大致工作流程为:首先将输入序列送入 encoder 提取语义特征,encoder的输出隐藏状态作为decoder的条件输入。为了加速文本生成,decoder 一侧放宽了 autoregressive 的约束,并以一组充满虚拟token(如[pad])的序列作为输入,启动迭代的并行解码过程。在每次迭代中,基于由 encoder 输出隐藏状态设定的条件,一些 token 能够被”确信地"预测并“解掩码”(unmasked)。解码后的token与未解码的masked token混合,剩余的masked token再次输入解码器,直到所有token都被解码完成。输入到 decoder 的fertility(序列长度),要么在 encoder 中通过一个特殊的 [CLS] token 来学习,要么通过 encoder 和 decoder 之间的专门 fertility predictor 来学习。
此外,Step-unrolled Denoising Autoencoders for Text Generation 工作中将 decoder 视为一个 diffusion model,并训练它根据给定的条件对噪声初始序列进行去噪。
然而,由于需要使用 encoder hidden states 作为并行解码的条件,NAT 方法在直接扩展到 decoder-only architectures 时存在不小困难。
4 Compiler/System Optimization
这个章节主要探讨一些广泛使用的编译器优化和系统优化技术。
4.1 Operator Fusion
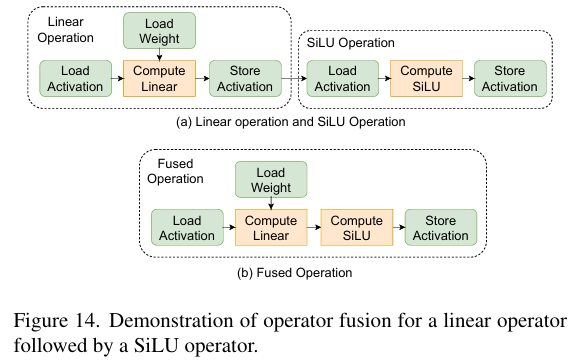
算子融合(Operator fusion)是深度学习框架中一项重要的编译时优化技术。它的核心思想是将计算图中直接相连的多个算子或层合并在一起,从而减少数据移动和中间表示。例如,可以将linear算子和SiLU算子融合为单个算子,这样可以避免存储和加载算子之间的中间激活值,从而减少内存消耗和访问。根据roofline模型,kernel融合能够提高arithmetic intensity,在 memory-bound 区域显著提升推理性能,但在计算受限区域则收益有限。

然而,算子融合并非适用于所有场景。比如当中间结果被其他计算需要时就无法进行融合;而且融合可能增加 on-chip buffer 需求;而且还受到框架和硬件架构的限制。虽然像 TVM 这样的编译工具能够自动识别和融合算子,但对于结构固定的LLM来说,使用特定的融合模式更为合适。
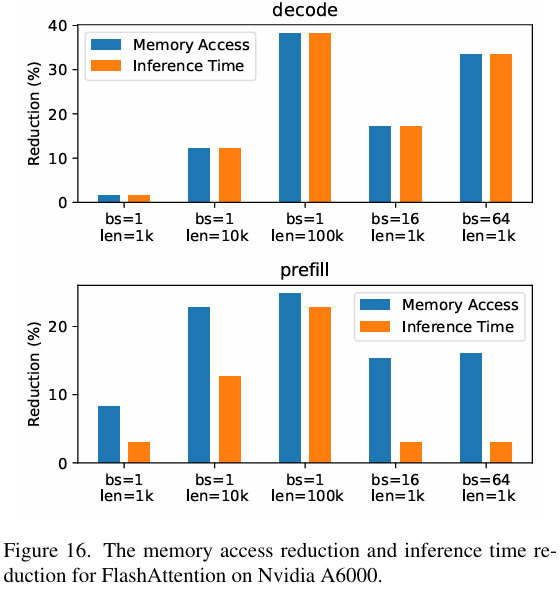
在LLM领域,已经出现了多种优化方案。FlashAttention 和 Flash-Decoding 提出了将self-attention中的矩阵乘法和softmax算子融合的方法,显著减少了内存访问和推理时间。另外我们还可以观察到在 prefill 阶段和 decode 阶段存在明显差异:在 decode 阶段,内存访问的减少与推理时间的减少程度基本一致。但是在 prefill 阶段,推理时间的减少幅度要低于内存访问的减少幅度。这主要是因为 prefill 阶段中的许多操作是 compute-bound 的,因此通过 operator fusion 来减少内存访问所带来的性能提升相对有限。
DeepSpeed-inference 则提出了Deep-Fusion技术,专门针对transformer层中的四个主要部分进行融合:QKV GeMM and input layer normalization;transposition and attention operations;post-attention layer normalization and intermediate GeMM;bias addition and residual addition.
xFormers 也提供了多种融合kernel,包括fused softmax、fused linear layer、fused layer norm和fused SwiGLU等。
TensorRT-LLM 则通过强大的模式匹配算法来检测各种LLM中的潜在融合机会。
除了kernel融合外,优化算子实现也是提升LLM性能的重要方向。例如,FlashDecoding++ 提出使用异步softmax和带双缓冲的flat GEMM优化来提高效率。
4.2 Memory Management and Workload Offloading
在使用LLM进行推理时,输入输出的 token 数量具有不确定性,这使得每次处理的数据量都可能不同。特别是在 prefill 和 decode 阶段,序列长度会随着处理过程动态变化,这与传统神经网络中固定的tensor大小形成鲜明对比。针对如何高效应对这种动态变化的内存需求,也产生了许多优质工作:PagedAttention 通过 KV Cache 分块来实现高效的内存管理,并使用类似CPU虚拟内存的映射表来管理逻辑块和物理块的对应关系。
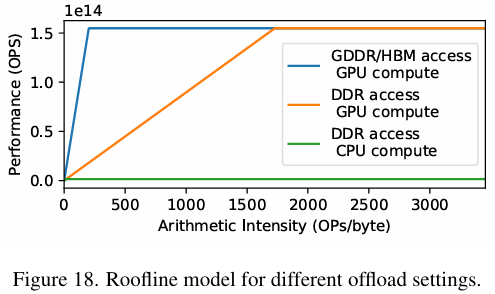
当GPU内存资源受限时,系统会将部分工作负载 offload 到其他存储空间,如CPU的DDR、GPU的GDDR/HBM或硬盘。这些不同的内存空间具有不同的访问带宽。下图说明,当数据被 offload 到CPU的DDR并在需要时再传输到GPU进行计算的这种方式比直接在CPU上进行计算更好。当batch size足够大时,arithmetic intensity会显著增加,使GPU能够充分利用其计算能力并取得良好的结果。
此外,DeepSpeed-inference 提出的 ZeRO-Inference 技术可以将模型权重 offload 到CPU内存中。这种机制在较大的 batch size 时处理表现良好,因为增加 batch size 的会提高计算需求,使得计算 latency 与获取模型权重的 latency 重叠,从而提高整体效率。
Huggingface Accelerate 在GPU空间不足以存储整个模型时,可以将特定模块移动到CPU或磁盘。
FlexGen 提供了一种探索不同计算 offload 方式的方法,考虑了GPU、CPU和磁盘等硬件资源的限制。为了找到最佳的吞吐量策略,FlexGen使用基于线性规划的搜索算法。
还有学者利用了 flash memory 相比DRAM更大的容量优势。它通过将模型参数存储在 flash memory 中,并在需要时将其传输到DRAM,从而实现高效推理。
4.3 Parallel Serving
在处理多用户对服务器的并发请求时,需要重点关注 response latency(响应延迟)和 throughput(吞吐量)两个核心指标。响应延迟指的是服务器响应每个用户请求所需的时间,而吞吐量则表示服务器在特定时间内能够处理的请求数量。提高服务器的吞吐量能够同时服务更多用户,从而提升整体系统性能。在优化 serving system 时,需要在最大化吞吐量的同时,确保响应延迟保持在可接受范围内。
Batching 是提升吞吐量的一种基本方法,它通过将多个用户请求打包一起处理来提高效率。研究表明,在decode阶段增加 batch size 能显著提升吞吐量,但同时也可能导致响应延迟增加和内存消耗增大。为了优化batching方法,有学者提出了多种技术方案。例如,ORCA引入了 continuous batching(也称为 iterative batching 或 rolling batching)来组合来自不同用户的推理请求;SARATHI 则采用了 chunked-prefills 和 decode-maximal batching 的方法,通过组合 prefill chunks 和 decode 请求来创建 batches,从而提高 arithmetic intensity 和吞吐量。类似地,DeepSpeed-FastGen 和 LightLLM 也采用了split and fuse技术来优化性能。
5 Hardware Optimization
由于不同推理阶段和工作负载条件下的 arithmetic intensity 存在差异,所以针对性的硬件设计也会相对复杂。具体来说,prefill阶段通常使用 GEMM 算子来处理批量化的tokens,表现出较高的 arithmetic intensity ;而 decoding 阶段则是逐个计算输出 tokens,需要使用 GEMV 算子或精简的 GEMM 算子来处理 attention 和 FFN 层,这些算子的 arithmetic intensity 较低。
此外,batch size 和序列长度的变化也会导致 arithmetic intensity 产生显著波动。较大的 batch size 可能会明显改变 arithmetic intensity,而较长的序列长度则可能增加每个 decoding 步骤中 KV Cache 读取的内存访问开销。这种变化为硬件设计带来了额外的复杂性,不同的阶段或配置可能需要不同的优化策略。因此在设计硬件时必须综合考虑这些因素以确保在各种场景下都能实现较为高效的性能。基于这些挑战,我们需要仔细考虑和优化硬件设计。本章节将对用于对高效 LLM inference 的各种硬件优化方案进行分析,重点关注解决 arithmetic intensity 变化相关的问题。
5.1 Spatial Architecture
在LLM decoding 过程中,模型需要基于之前生成的 token 来逐个预测新的token。这个过程由于需要访问大量的权重和key-value (KV) cache,导致 arithmetic intensity 较低,计算成本较高,特别是在生成长序列时更为明显。为了解决这个问题,有学者提出了 “Spatial Architecture”(空间架构)的解决方案。与传统计算架构不同,空间架构采用了一种新的计算方法,它不通过 processing elements (PEs) 和主存储器之间的多次交互来完成计算,而是将计算分布在多个 PEs 上。这种设计允许并行计算,因为每个 PE 可以同时执行部分计算任务,而且中间数据可以直接在 PEs 之间流动,避免了频繁地写回 DRAM。在空间架构中,每个 PE 负责特定的计算部分,数据主要在相邻的 PEs 之间传输,这提高了性能和资源利用率;每个PE都有自己的内存访问通道,这使得多个 PEs 能够同时访问内存,从而提高了数据传输速度和内存带宽,最终提升了 LLM 推理性能。
目前 Spatial Architecture 已有多个成功的实现案例,如 Groq 公司使用他们的 LPU 构建的空间系统,能够在 Llama-2-70b 模型上达到每个用户每秒超过300个token的处理速度。另一个例子是 Graphcore 的Intelligence Processing Unit (IPU),这也是一种能够高效执行LLM的空间架构。
5.2 Processing in Memory
由于 arithmetic intensity 较低,LLM推理的decoding阶段也存在着困扰体系结构领域几十年的 “Memory Wall” 问题。作为解决方案之一,Processing in-memory (PIM) 技术近年来受到广泛关注。通过在内存芯片中直接放置计算单元,可以利用更高的内部内存带宽,减少内存与 CPU/GPU 核心之间的数据移动开销。
在商业化方面,UPMEM的PIM-DIMM 是首个商用 DRAM-PIM 产品,它在 DDR4-DIMM 中放置了通用 RISC 核心。而 Samsung 提出的 HBM-PIM 方案则在 HBM 内存中集成 MAC 单元,实现了2TB/s的内部内存带宽,远高于传统 HBM2 的性能。SK-hynix推出的 GDDR6 基础的 AiM 加速器采用BF16数据格式,每芯片提供1TFLOPS的计算能力和1TB/s的峰值带宽。
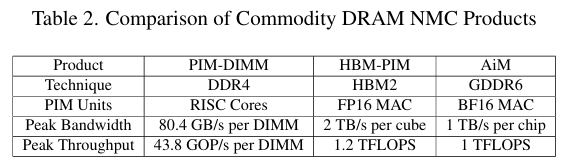
然而,DRAM-PIM 技术仍面临几个主要限制:
首先是计算能力受限,DRAM-PIM 使用 DRAM 工艺制造的计算单元,这导致其晶体管速度比同等工艺节点的 CMOS 慢3倍,且逻辑密度要低几倍。更糟糕的是,DRAM 芯片通常具有较少的金属层,这同时导致了较低的布线密度。由于这些技术限制,DRAM-PIM 难以集成强大的计算单元。因此,DRAM-PIM 仅适用于小批量推理或 KV Cache 处理。对于计算密集型的大批量推理任务,仍然需要强大的主机支持。
其次是容量限制,由于 DRAM-PIMs 需要分配一部分内存来构建计算单元,导致其总内存容量通常比标准内存少50%。这对于需要大量内存来存储权重和 KV Cache的 LLM 应用来说是一个巨大挑战。
最后是PIM单元间通信能力不足,由于 DRAM-PIMs 在每个 DRAM bank 附近都有分布式计算单元,这些单元之间的数据聚合和计算同步是不可避免的。然而,DRAM-PIMs 缺乏强大的互连机制,通常需要依赖主机 CPU/GPU 来实现 PIM 单元之间的数据交换,这种依赖会导致系统效率降低。因此,为了提升 LLM 推理性能,未来的 DRAM-PIMs 设计需要着重改进其 inter-PIM 通信能力。
5.3 New Data Format
传统上,神经网络训练通常使用高精度的 floating point 数据格式(16位或32位),这种格式虽然能同时保证精度和范围,但其复杂的硬件实现并不利于高效推理。为了降低硬件开销,uniform quantization 将高精度浮点数转换为低精度整数表示,用更高效的整数运算替代昂贵的浮点运算。然而 uniform quantization 难以同时平衡表示精度和范围,这往往会导致模型精度显著下降。而且,为了保持模型精度不显著降低,需要精心设计量化算法,这增加了额外的转换成本。non-uniform quantization 试图通过 assigning bits and discretizing the range of parameters non-uniformly 来提高 low bit 条件下的数据表示精度,但其在通用计算硬件(如CPU和GPU)上的部署较为困难。总的来说,现有的数据格式难以同时实现高精度、广范围、高效率和低调优成本。
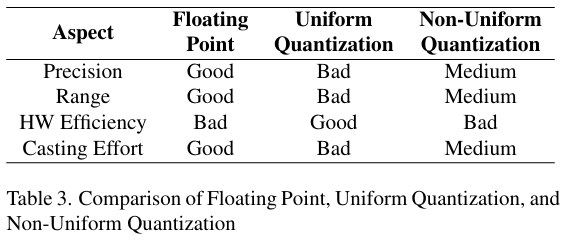
考虑到降低 LLM 部署成本的重要性,研究人员在探索更平衡的数据格式方面做了大量工作。最自然的改进方向是减少高精度浮点格式中的指数位和尾数位。近期研究表明,各类预训练模型(包括LLMs)可以直接从 FP16 量化到 FP8 而不会显著损失精度。在更广泛的任务中,FP8 训练可以有效达到16位训练的质量水平。低精度浮点格式在硬件效率方面的显著提升和较低的使用门槛已经引起了AI硬件制造商的关注。例如,NVIDIA在H100 GPU中实现了FP8 Tensor Core,Tesla也在其Dojo芯片中引入了 configurable 的浮点格式CFloat8。
除了工业界引入的新架构之外,学术界也有许多在 LLM 上开发低精度浮点格式潜力的工作:如 ZeroQuant-FP 提出的FP4和FP8权重/激活量化方法(采用了权重量化的缩放约束,实现了从FP4到FP8的高效权重转换,并更好地利用了FP8 Tensor Core),ZeroQuant-(4+2) 和 FP6-LLM 提出的FP6权重量化方案,以及 LLM-FP4 提出的FP4权重/激活量化方法。这些工作证明了在更低位宽的浮点格式下进行量化的可行性,以及在现有或新硬件平台上实现更高效率的潜力。
另一方面也有一些工作致力于改进低精度量化格式,以增强数据表示的 adaptability 同时保持硬件效率。一些研究提出了在 single value representation 中新的编码方案。与 INT 和 FP 数字使用固定长度 sub-fields 不同,新提出的量化格式允许 sub-fields 位宽的动态调整。例如,ALPS 提出了 generalized posit format 和新的自适应量化算法,ANT 提出了带有 leading-1 编码的 flint 数据格式,Dybit 提出用首个遇到的0作为分隔符来分离指数和尾数字段。这些可变长度数据格式提供了在范围和精度之间更有效折中的机会。
还有一类研究则主要关注 values 之间的相似性和差异性。基于 Outlier-aware 的量化方法注意到具有较大幅度的值对模型性能有显著影响,在这类方法中,重要的值被识别为 outliers,并与正常值区别对待以确保更准确的表示。
比如 OLAccel 和 GOBO 分别存储并为 outliers 分配更高的位宽,OliVe 通过 outlier-victim pair 编码方案改进了这一概念。
Bit-sharing 编码则关注值之间的内在相似性,通过在粗粒度上添加额外信息来实现表示精度和硬件效率之间的平衡;AdaptivFloat 提出使用共同的 tensor-wise exponent bias 来优化 FP 值的可用范围;而 MX 则基于这一观察扩展到更细的粒度,提出了 Block Data Representation (BDR) 框架,以探索表示精度和硬件效率之间的最优权衡。

5.4 New Processing Element
除了对内存访问的高需求外,开发专门的 PEs(处理单元)来提升计算能力也是一个备受关注的方向。这些 specialized 架构旨在针对 LLM 相关的特定运算,相比通用处理单元(如CUDA core)可以更显著地提升计算性能。
NVIDIA在其H100 GPU中开发了一个称为 Transformer Engine 的特殊硬件加速引擎。该引擎使用统计分析来确定模型每一层的最优精度(FP16或FP8),在保持准确性的同时实现最佳性能;一些研究人员专门设计了相关加速器,用于高效执行语言模型中的注意力机制,如 Fact,Flat;多家公司和研究团队也在探索使用 FPGA 来加速 LLM 计算,比如 DFX 和 LightLLM 等项目。
6 Discussion
6.1 Reliability
Model Compression章节 中提到的压缩技术显著提高了 LLMs 在实际应用场景中的推理和训练效率,但这些技术也会对模型的可靠性产生一定的影响。本节主要关注这些不同压缩技术中的设计选择如何影响以下三个可靠性方面:hallucination(幻觉)、safety alignment(安全对齐)和 out-of-distribution generalization(分布外泛化)。Hallucination主要指 LLMs 的输出与现实世界知识不符的情况,往往会生成事实错误或无意义的内容;Safety alignment关注模型自主识别和拒绝回应有害询问的能力,从而防止生成不当或危险的内容;OOD Generalization主要指压缩后的模型在处理常见情况时表现还不错,但在处理一些特殊或少见情况时,准确率会明显下降。
6.1.1 Hallucination(幻觉)
为了抑制幻觉现象,关键在于关注 Transformer 模型中事实性知识的存储位置。研究表明,这些知识通常存储在 Feed-Forward Networks (FFNs) 中。因此在应用量化或结构化压缩方法时,必须特别注意 FFN 层的输出校准。对此,一种有效的策略是去专门识别模型中关键的 FFN 层。有学者提出了一种 neuron-level 的解释技术,可以用来确定这些关键层的重要特征,之所以需要特别关注这些层,是因为它们包含了模型准确回忆和使用事实信息所需的核心权重。针对这些关键 FFN 层,可以采取选择性量化的方式,即在整体模型进行量化以减少规模和计算需求的同时,对这些关键层的量化精度进行调整,保持更高的精度。这种方法能够在压缩模型的同时,最大限度地保留事实知识的完整性和准确性,从而有效降低输出产生幻觉的风险。
此外,在通过剪枝删除不重要的权重或神经元以简化模型时,保留这些关键 FFN 层同样至关重要。通过保留这些层模型能够维持其回忆和处理事实知识的核心能力,从而确保输出的准确性并减少幻觉内容的生成。这种选择性保留和优化的策略,对于提升模型性能和可靠性具有重要意义。
6.1.2 Safety Alignment
初期有学者研究发现,适度的模型压缩(如8-bit quantization)并不会显著影响模型的安全能力。然而根据 Jailbreaker 工作的研究,这种压缩可能会使模型更容易受到某些 jailbreak attacks(越狱攻击)的影响,这是先前研究涉及较少的领域。因此在部署这些压缩后的模型之前,建议进行全面的 red teaming(红队测试)。此外基于 knowledge transfer(知识迁移)的方法可能会显著削弱模型的安全性。因此,建议在完成知识迁移后,对较小的模型进行重新微调以确保安全。
6.1.3 OOD Generalization
当 LLMs 部署在实际场景中时,往往会受到 decision shortcuts 的影响,导致在 long-tail subgroup distributions 中产生错误判断。
[!NOTE]
这句话可以这样理解:LLMs在实际应用时,倾向于采用一些"捷径式"的简单决策方式(decision shortcuts),而不是进行深入的分析。这种简化的决策方式在处理常见情况时可能没问题,但在处理那些不常见或特殊的情况(long-tail subgroup distributions,长尾分布)时,容易做出错误的判断。
研究表明,当神经网络模型被量化压缩后,在处理不同子群体的任务时,表现会出现明显差异。特别是对于那些依赖上下文中"捷径决策"的长尾(较少见)子群体,模型更容易出现判断错误。此外,在实践中为提高大型语言模型推理效率而广泛使用的 KV Cache 压缩技术,通过在推理过程中随机丢弃 attention matrix 中的 tokens,进一步加剧了模型对 decision shortcuts 的依赖。因此,建议在特定的下游应用场景中考虑集成相应的鲁棒性增强方法,例如之前研究中提到的 invariant test-time optimization 技术。
6.2 Efficient Large Multimodal Models
6.2.1 Large Multimodal Models (LMMs)
大型多模态模型(Large Multimodal Models, LMMs),尤其是视觉语言模型(Visual Language Models, VLMs),正成为构建通用智能助手的一个极具潜力的方向。这类模型展现出了显著增强的感知与推理能力,其核心依赖于大语言模型(LLMs)的强大认知能力。通过优秀的语言生成、零样本迁移(zero-shot transfer capabilities)以及上下文学习(In-Context Learning)能力,LLMs 为多模态任务提供了丰富的支持。同时不同模态的基础模型也为任务提供了高质量的表征。然而 LMMs 面临的一个关键挑战在于如何高效整合 LLMs 与其他模态的模型,以实现协同推理。目前的研究主要聚焦于通过多模态预训练(MM Pre-Training)和多模态指令微调(MM Instruction-Tuning)来优化模态对齐,并确保模型能够更好地理解和符合人类意图。
6.2.2 Efficient LMMs
尽管 LMMs 取得了显著进展,但其训练和部署均需要大量计算资源,这促使了 efficient parallel device 实现的需求。Google的 Gemini 在 efficient LMMs 领域处于领先地位,在多模态基准测试中达到了最优性能,并推出了适用于低内存设备的移动级 LMMs,但它是闭源的。开源项目如 LLaVA-v1.5 采用了压缩技术,包括通过 bitsandbytes 实现的4/8位量化;在 efficient LMMs 的进一步探索中,MobileVLM 开发了紧凑型 LLMs 和高效的多模态特征 projector,其后续版本 MobileVLM-v2 探索了移动场景下改进的训练策略;TinyGPT-V 利用 Phi-2 LLM 实现了超越更大模型的性能;同样,LLaVA-Phi 和 Vary-toy 引入了更小的 backbones 和增强的词汇表以提高泛化能力;TinyLLaVA 研究了架构选择、数据质量和训练策略的影响,证明较小的 LMMs 通过优化数据和训练可以匹配更大模型的性能;MoE-LLaVA 则采用了Mixture of Experts (MoE)技术来缓解模型因稀疏性导致的性能下降问题。
6.3 Long Context Modeling
在用于 Chatbot 或文档摘要工具等任务时,LLMs 在长文本上下文建模和推理能力方面面临着挑战。这些模型通常是在通用预训练语料库上训练的,而这些语料库通常由较短的文本片段组成,无法为 LLM 提供足够高质量的长文本训练样例。为了改善预训练模型在长文本处理能力方面的不足,众多研究从不同角度尝试解决这个问题。在这部分讨论中,作者主要关注于 alternative attention mechanisms, cache compression, context retrieval, position encoding modifications这几个方面。更详细的内容可以参考:Advancing Transformer Architecture in Long-Context Large Language Models: A Comprehensive Survey
6.3.1 Alternative Attention Design
Transformer架构的核心在于其self-attention机制。然而,在使用 KV Cache 的 decoder-only 模型进行推理,当历史上下文变得较长时,模型需要关注所有历史的 keys 并与 past values 进行计算,这往往会带来计算和内存上的瓶颈。此前有研究表明,实际上要保持模型的推理性能,并不需要对所有的历史 tokens 都进行关注。
Landmark Attention 通过在序列中引入特殊的landmark标记来总结后续tokens的信息,新的 query 会先关注landmark标记以决定是否需要关注块内的其他token;Funnel-Transformer 则通过在encoder部分引入下采样和在decoder部分引入上采样来实现类似目标Longformer 和 ETC 采用了不同的方式来结合滑动窗口注意力和全局注意力,前者允许预定义的 token 关注所有序列,后者引入了二级层次结构;LongT5 提出了一种更简单的方法,直接通过 mean pooling 对长序列上下文进行下采样;StreamingLLM 和 **LM Infinite **同时提出了 sink 加滑动窗口的注意力模式,特别是StreamingLLM指出了输入序列开始部分的 token 对维持自注意力性能至关重要。H2O则通过仅关注先前prefill输入上下文中感兴趣的 token 来降低自注意力的计算复杂度。这些方法都在不同程度上解决了长序列处理中的效率问题,并在保持模型性能的同时降低了计算成本。
6.3.2 Recurrence and Retrieval
Transformer-XL 通过引入 segment-level recurrence 结构来提升语言模型处理长文本的能力,其方法是存储前一个段落的最后一层输出并将其附加到当前层,从而显著增加了模型的 dependency distance;在此基础上,Segatron 通过 segment-aware 机制在 token 层级、句子层级及更高层级上增强了 segment-level recurrence;而 Compressive Transformer 则提出了 second-level compressed memory FIFO queue 的概念,通过自定义压缩函数将过去的段落上下文存储在队列中而不是直接丢弃,从而延长了 dependency distance;Dynamic Memory Compression 延续了这一递归思想,通过压缩上下文来动态决定如何压缩先前的上下文信息,在保留远距离信息的同时减少了注意力机制的序列长度。除了 segment-level 的改进,还有学者研究了retrospective recurrence,如 Memorizing Transformer 和 Memformer 将检索和本地缓存与遗忘机制相结合。
除此以外,基于“并非每个历史token都对当前token生成至关重要”的观点,过去的 KV Cache 可以被存储在物理距离更远的二级存储中,仅在需要时检索特定的 key-value 对。因此提升 LLM 性能的另一种方式就是通过 Retrieval-Augmented Generation (RAG)。RAG 是一种结合了信息检索技术与语言生成模型的人工智能技术,该技术通过从外部知识库中检索相关信息,并将其作为 Prompt 输入给LLMs,以增强模型处理知识密集型任务的能力。为了解决 LLMs 在长文本处理能力上的局限性,LangChain 成为一种缓解Chatbot长对话历史问题的流行解决方案,LangChain是一个开源工具,能够利用 LLMs 为用户输入的长文档或文件计算 embedding,并通过 cosine-similarity metrics 检索最相关的内容来响应用户的提示。
6.3.3 Maneuvering Position Encodings
在预训练过程中,Transformer 的位置编码只能处理固定长度限制内的输入序列,且由于位置编码通常基于三角函数,vanilla transformer 无法有效扩展到更长的序列长度。早期的解决方案是在 softmax 操作前向 attention map 添加注意力偏置。其中,**ALiBi **引入了 heuristics 来设计这种注意力偏置,在 long-context extrapolation 任务中取得了初步成功。随后,Kerple 和 Sandwich 在前人工作基础上引入了可训练参数来构建注意力偏置矩阵,或通过位置编码的正弦特性构建注意力偏置。
另一个研究方向致力于改进 RoPE(旋转位置编码)。受到 Neural Tangent Kernel (NTK) 理论启发,NTK-aware Scaled RoPE 对RoPE的基础参数进行了修改;LEX 和 PermuteFormer 添加了指数衰减项;Positional Interpolation 对每个token进行 linear scaling;Dynamic-NTK 逐步增加 scaling 比率;YaRN 通过温度因子对 query 和 key 进行 linear scaling;Giraffe 发现 high-frequency terms 容易受到训练不充分的 low-frequency terms 影响,因此提出了基于幂律的 scaling mechanism 来保护训练充分的高频信息。