PowerInfer_AMD_Optimization
Environment:
aupxtx@aupxtx:~$ python3 -m torch.utils.collect_env
Collecting environment information...
PyTorch version: 2.3.0+rocm5.7
Is debug build: False
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: 5.7.31921-d1770ee1b
OS: Ubuntu 22.04.3 LTS (x86_64)
GCC version: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Clang version: 17.0.0 (https://github.com/RadeonOpenCompute/llvm-project roc-6.0.2 24012 af27734ed982b52a9f1be0f035ac91726fc697e4)
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] (64-bit runtime)
Python platform: Linux-6.2.0-26-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: Radeon RX 7900 XTX (gfx1100)
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: 5.7.31921
MIOpen runtime version: 2.20.0
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 7 7800X3D 8-Core Processor
CPU family: 25
Model: 97
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
Stepping: 2
Frequency boost: enabled
CPU max MHz: 5049.0229
CPU min MHz: 3000.0000
BogoMIPS: 8399.69
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good amd_lbr_v2 nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate ssbd mba perfmon_v2 ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local avx512_bf16 clzero irperf xsaveerptr rdpru wbnoinvd cppc arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif x2avic v_spec_ctrl avx512vbmi umip pku ospke avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg avx512_vpopcntdq rdpid overflow_recov succor smca fsrm flush_l1d
Virtualization: AMD-V
L1d cache: 256 KiB (8 instances)
L1i cache: 256 KiB (8 instances)
L2 cache: 8 MiB (8 instances)
L3 cache: 96 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-15
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP always-on, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.26.3
[pip3] pytorch-triton-rocm==2.3.0
[pip3] torch==2.3.0+rocm5.7
[pip3] torchaudio==2.3.0+rocm5.7
[pip3] torchvision==0.18.0+rocm5.7
Opt Log
1. Find bad performance on 7900XTX
Test with llama-7b-relu.powerinfer.gguf and llama-7b-relu.q4.powerinfer.gguf
7900 result without quant:
llama_print_timings: load time = 1408.45 ms
llama_print_timings: sample time = 12.29 ms / 128 runs ( 0.10 ms per token, 10419.21 tokens per second)
llama_print_timings: prompt eval time = 74.36 ms / 5 tokens ( 14.87 ms per token, 67.24 tokens per second)
llama_print_timings: eval time = 4499.95 ms / 127 runs ( 35.43 ms per token, 28.22 tokens per second)
llama_print_timings: total time = 4601.82 ms
4090 result without quant:
llama_print_timings: load time = 6310.50 ms
llama_print_timings: sample time = 14.17 ms / 128 runs ( 0.11 ms per token, 9034.44 tokens per second)
llama_print_timings: prompt eval time = 18.50 ms / 5 tokens ( 3.70 ms per token, 270.20 tokens per second)
llama_print_timings: eval time = 1609.02 ms / 127 runs ( 12.67 ms per token, 78.93 tokens per second)
llama_print_timings: total time = 1660.44 ms
7900 result with Q4 quant:
llama_print_timings: load time = 495.59 ms
llama_print_timings: sample time = 12.43 ms / 128 runs ( 0.10 ms per token, 10301.81 tokens per second)
llama_print_timings: prompt eval time = 80.97 ms / 5 tokens ( 16.19 ms per token, 61.75 tokens per second)
llama_print_timings: eval time = 2831.35 ms / 127 runs ( 22.29 ms per token, 44.85 tokens per second)
llama_print_timings: total time = 2935.92 ms
4090 result with Q4 quant:
llama_print_timings: load time = 428.45 ms
llama_print_timings: sample time = 15.35 ms / 128 runs ( 0.12 ms per token, 8337.68 tokens per second)
llama_print_timings: prompt eval time = 14.47 ms / 5 tokens ( 2.89 ms per token, 345.57 tokens per second)
llama_print_timings: eval time = 898.83 ms / 127 runs ( 7.08 ms per token, 141.29 tokens per second)
llama_print_timings: total time = 947.09 ms
| Llama + 4090 | Llama + 7900 | PowerInfer + 4090 | PowerInfer + 7900 | |
|---|---|---|---|---|
| Performance | 79 tokens/s | 61 tokens/s | 78.93 tokens/s | 28.22 tokens/s |
| Performance with Q4 quant | 140 tokens/s | 110 tokens/s | 141.29 tokens/s | 44.85 tokens/s |
2. Profile with ROCprofv2
$ rocprofv2 -h
ROCProfilerV2 Run Script Usage:
-h | --help For showing this message
--list-counters For showing all available counters for the current GPUs
-m For providing an absolute path of a custom metrics file
--basenames For Truncating the kernel names
--hip-api For Collecting HIP API Traces
--hip-activity | --hip-trace For Collecting HIP API Activities Traces
--hsa-api For Collecting HSA API Traces
--hsa-activity | --hsa-trace For Collecting HSA API Activities Traces
--roctx-trace For Collecting ROCTx Traces
--kernel-trace For Collecting Kernel dispatch Traces
--sys-trace For Collecting HIP and HSA APIs and their Activities Traces along ROCTX and Kernel Dispatch traces
#usage e.g: rocprofv2 --[hip-trace|hsa-trace|roctx-trace|kernel-trace|sys-trace] <executable>
--plugin PLUGIN_NAME For enabling a plugin (cli/file/perfetto/att/ctf)
# usage(file/perfetto/ctf) e.g: rocprofv2 -i pmc.txt --plugin [file/perfetto/ctf] -d out_dir <executable>
# usage(att): rocprofv2 <rocprofv2_params> --plugin att <ISA_file> <att_parameters> <executable>
# use "rocprofv2 --plugin att --help" for ATT-specific parameters help.
--plugin-version <1|2> For selecting the version for the plugin (1/2)
# 1 - Legacy output format, 2 - New output format (default)
-i | --input For adding counters file path (every line in the text file represents a counter)
# usage: rocprofv2 -i pmc.txt -d <executable>
-o | --output-file For the output file name
# usage e.g:(with current dir): rocprofv2 --hip-trace -o <file_name> <executable>
# usage e.g:(with custom dir): rocprofv2 --hip-trace -d <out_dir> -o <file_name> <executable>
-d | --output-directory For adding output path where the output files will be saved
# usage e.g:(with custom dir): rocprofv2 --hip-trace -d <out_dir> <executable>
-fi | --flush-interval For adding a flush interval in milliseconds, every "flush interval" the buffers will be flushed
# usage e.g: rocprofv2 --hip-trace -fi 1000 <executable>
-tp | --trace-period Specifies a trace period in milliseconds, with format "-tp <DELAY>:<ACTIVE_TIME>:<LOOP_RESET_TIME>".
# usage e.g: rocprofv2 --hip-trace -tp 1000:2000:4000 <executable>
I used this script for profiling:
#!/bin/bash
rm -rf build
CC=/opt/rocm/llvm/bin/clang CXX=/opt/rocm/llvm/bin/clang++ cmake -S . -B build -DLLAMA_HIPBLAS=ON -DAMDGPU_TARGETS=gfx1100
cmake --build build --config Release
rocprofv2 -d ./profile/ --hip-trace --hip-api --plugin perfetto ./build/bin/main -m ./ReluLLaMA-7B/llama-7b-relu.powerinfer.gguf --ignore-eos -n 256 --seed 0 --top-k 1 --reset-gpu-index -t 8 -p "Once"
First I got this result:
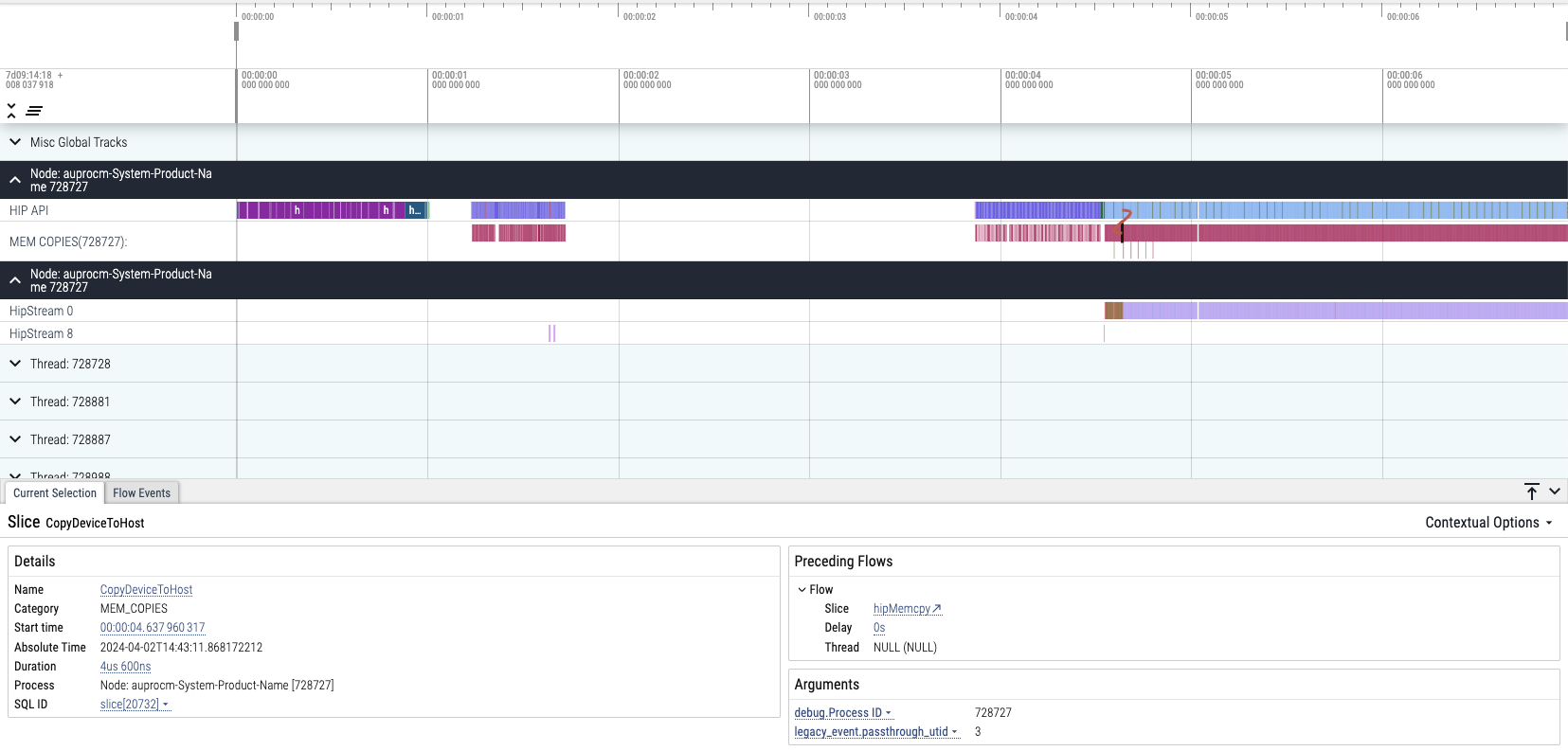
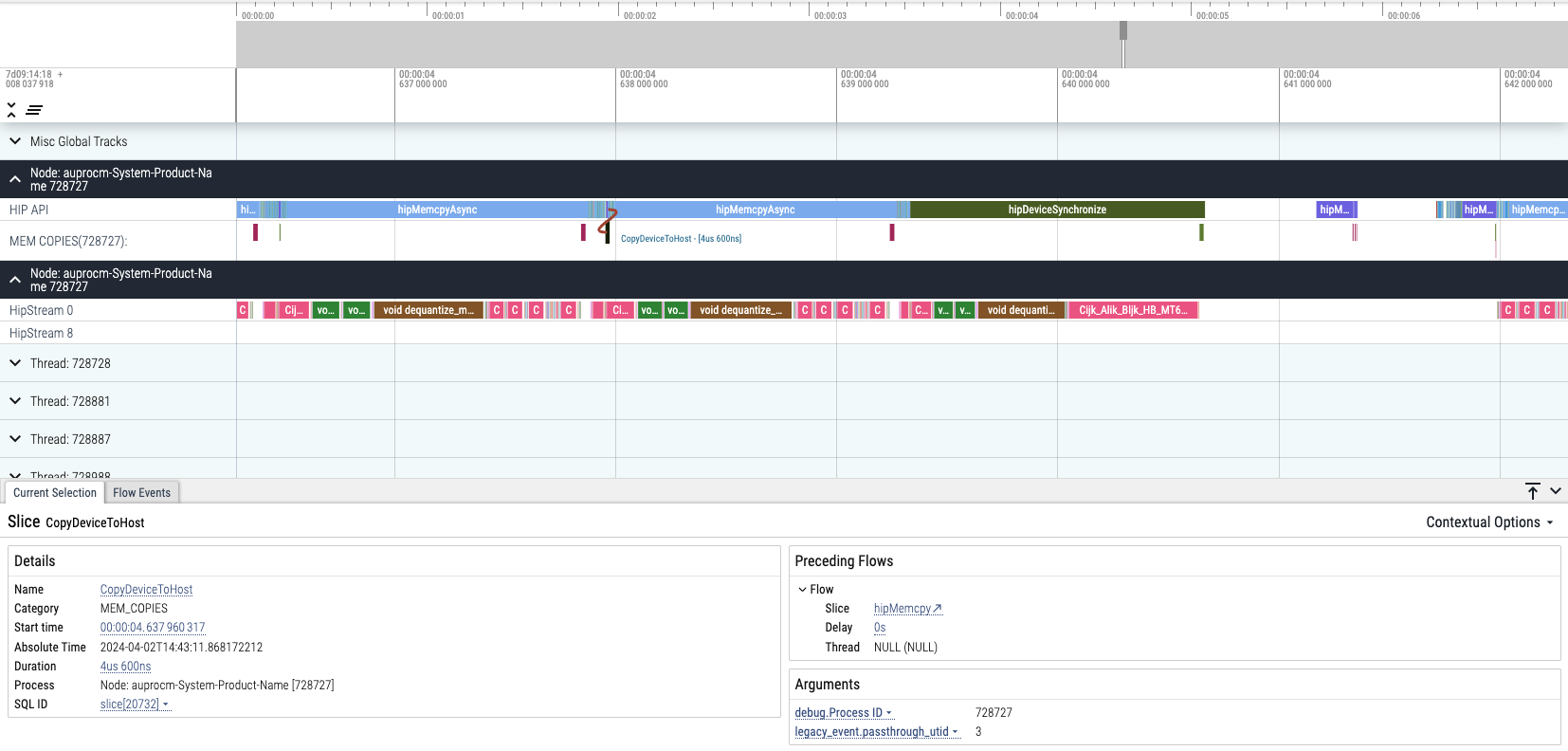
We can see that hipMemcpyAsync hip-api and CopyHostToDevice event dominated the program.
However, as theoretically analysis and contexts show:
total VRAM used: 22793.02 MB (model: 14195.52 MB, context: 341.50 MB)
VRAM used < 7900xtx VRAM(24G)
The model and all info should be loaded to GPU at the beginning rather too many Memcpy invokes at latter stage.
So we need to confirm whether this happen as we expected.
3. Backend detection
I refered with tensor architecture and use the code snippet after the end of the load period to insert and print Tensor backend device information to monitor whether the data has been loaded into the GPU as expected:
if (src->backend == GGML_BACKEND_CPU) {printf(src->name);printf(" src_CPU\n");}
else if (src->backend == GGML_BACKEND_GPU || src->backend == GGML_BACKEND_GPU_SPLIT) {printf(src->name);printf(" src_GPU\n");}
if (dst->backend == GGML_BACKEND_CPU) {printf(dst->name);printf(" dst_CPU\n");}
else if (dst->backend == GGML_BACKEND_GPU || dst->backend == GGML_BACKEND_GPU_SPLIT) {printf(dst->name);printf(" dst_GPU\n");}
And the result:
src0_GPU
src1_GPU
dst_GPU
src0_GPU
src1_GPU
dst_GPU
src0_GPU
src1_GPU
dst_GPU
src0_GPU
src1_GPU
dst_GPU
src0_GPU
src1_GPU
dst_GPU
src0_GPU
src1_GPU
dst_GPU
src0_GPU
src1_GPU
dst_GPU
src0_GPU
src1_GPU
dst_GPU
src0_GPU
src1_GPU
result_output dst_CPU
This showed that these tensors are indeed loaded to GPU(Last CPU is used to output info).
Besides, I also analyzed with Computation Graph:
7900
=== GRAPH ===
n_nodes = 1220
- 0: [ 4096, 1, 1] GET_ROWS inp_embd ( 1) cpu = 0.000 / 0.000 ms, wall = 0.006 / 0.006 ms
- 1: [ 4096, 1, 1] RMS_NORM norm-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.034 / 0.034 ms
- 2: [ 4096, 1, 1] MUL attn_norm-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.021 / 0.021 ms
- 3: [ 4096, 1, 1] MUL_MAT Vcur-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.097 / 0.097 ms
- 4: [ 4096, 1, 1] RESHAPE Vcur-0 (reshaped) ( 1) cpu = 0.000 / 0.000 ms, wall = 0.001 / 0.001 ms
- 5: [ 1, 4096, 1] TRANSPOSE v_cur_t-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.000 / 0.000 ms
- 6: [ 1, 4096, 1] VIEW v_cache_view-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.000 / 0.000 ms
- 7: [ 1, 4096, 1] CPY v_cache_view-0 (copy of v_cur_t-0) ( 1) cpu = 0.000 / 0.000 ms, wall = 0.021 / 0.021 ms
- 8: [ 32, 128, 32] VIEW v-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.001 / 0.001 ms
- 9: [ 4096, 1, 1] MUL_MAT Kcur-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.088 / 0.088 ms
- 10: [ 128, 32, 1] RESHAPE Kcur-0 (reshaped) ( 1) cpu = 0.000 / 0.000 ms, wall = 0.000 / 0.000 ms
- 11: [ 128, 32, 1] ROPE Kcur-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.021 / 0.021 ms
- 12: [ 4096, 1, 1] VIEW k_cache_view-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.000 / 0.000 ms
- 13: [ 4096, 1, 1] CPY k_cache_view-0 (copy of Kcur-0) ( 1) cpu = 0.000 / 0.000 ms, wall = 0.019 / 0.019 ms
- 14: [ 128, 32, 32] VIEW k-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.000 / 0.000 ms
- 15: [ 4096, 1, 1] MUL_MAT Qcur-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.102 / 0.102 ms
- 16: [ 128, 32, 1] RESHAPE Qcur-0 (reshaped) ( 1) cpu = 0.000 / 0.000 ms, wall = 0.000 / 0.000 ms
- 17: [ 128, 32, 1] ROPE Qcur-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.023 / 0.023 ms
- 18: [ 128, 1, 32] PERMUTE q-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.000 / 0.000 ms
- 19: [ 32, 1, 32] MUL_MAT kq-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.029 / 0.029 ms
- 20: [ 32, 1, 32] SCALE kq_scaled-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.029 / 0.029 ms
- 21: [ 32, 1, 32] ADD kq_masked-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.021 / 0.021 ms
- 22: [ 32, 1, 32] SOFT_MAX kq_soft_max-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.022 / 0.022 ms
- 23: [ 128, 1, 32] MUL_MAT kqv-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.030 / 0.030 ms
- 24: [ 128, 32, 1] PERMUTE kqv_merged-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.000 / 0.000 ms
- 25: [ 4096, 1, 1] CONT kqv_merged_cont-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.021 / 0.021 ms
- 26: [ 4096, 1, 1] MUL_MAT kqv_out-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.090 / 0.090 ms
- 27: [ 4096, 1, 1] ADD ffn_inp-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.026 / 0.026 ms
- 28: [ 4096, 1, 1] RMS_NORM norm-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.022 / 0.022 ms
- 29: [ 4096, 1, 1] MUL ffn_norm-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.029 / 0.029 ms
- 30: [ 1024, 1, 1] MUL_MAT mlp_pre_hidden-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.051 / 0.051 ms
- 31: [ 1024, 1, 1] UNARY mlp_pre_relu-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.019 / 0.019 ms
- 32: [ 11008, 1, 1] MUL_MAT mlp_pre_out-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.117 / 0.117 ms
- 33: [ 11008, 1, 1] MUL_MAT_SPARSE ffn_gate_sparse-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.061 / 0.061 ms
- 34: [ 11008, 1, 1] UNARY ffn_gate_act-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.019 / 0.019 ms
- 35: [ 11008, 1, 1] MUL_MAT_SPARSE ffn_up_sparse-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.059 / 0.059 ms
- 36: [ 11008, 1, 1] MUL ffn_gate_par-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.021 / 0.021 ms
- 37: [ 4096, 1, 1] AXPY ffn_down_sparse-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.322 / 0.322 ms
- 38: [ 4096, 1, 1] ADD l_out-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.021 / 0.021 ms
- 39: [ 4096, 1, 1] RMS_NORM norm-1 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.020 / 0.020 ms
- 40: [ 4096, 1, 1] MUL attn_norm-1 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.019 / 0.019 ms
...
4090
=== GRAPH ===
n_nodes = 1220
- 0: [ 4096, 1, 1] GET_ROWS inp_embd ( 1) cpu = 0.000 / 0.000 ms, wall = 0.006 / 0.006 ms
- 1: [ 4096, 1, 1] RMS_NORM norm-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.014 / 0.014 ms
- 2: [ 4096, 1, 1] MUL attn_norm-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.006 / 0.006 ms
- 3: [ 4096, 1, 1] MUL_MAT Vcur-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.052 / 0.052 ms
- 4: [ 4096, 1, 1] RESHAPE Vcur-0 (reshaped) ( 1) cpu = 0.000 / 0.000 ms, wall = 0.001 / 0.001 ms
- 5: [ 1, 4096, 1] TRANSPOSE v_cur_t-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.000 / 0.000 ms
- 6: [ 1, 4096, 1] VIEW v_cache_view-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.001 / 0.001 ms
- 7: [ 1, 4096, 1] CPY v_cache_view-0 (copy of v_cur_t-0) ( 1) cpu = 0.000 / 0.000 ms, wall = 0.005 / 0.005 ms
- 8: [ 32, 128, 32] VIEW v-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.000 / 0.000 ms
- 9: [ 4096, 1, 1] MUL_MAT Kcur-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.048 / 0.048 ms
- 10: [ 128, 32, 1] RESHAPE Kcur-0 (reshaped) ( 1) cpu = 0.000 / 0.000 ms, wall = 0.000 / 0.000 ms
- 11: [ 128, 32, 1] ROPE Kcur-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.005 / 0.005 ms
- 12: [ 4096, 1, 1] VIEW k_cache_view-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.001 / 0.001 ms
- 13: [ 4096, 1, 1] CPY k_cache_view-0 (copy of Kcur-0) ( 1) cpu = 0.000 / 0.000 ms, wall = 0.005 / 0.005 ms
- 14: [ 128, 32, 32] VIEW k-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.000 / 0.000 ms
- 15: [ 4096, 1, 1] MUL_MAT Qcur-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.048 / 0.048 ms
- 16: [ 128, 32, 1] RESHAPE Qcur-0 (reshaped) ( 1) cpu = 0.000 / 0.000 ms, wall = 0.000 / 0.000 ms
- 17: [ 128, 32, 1] ROPE Qcur-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.005 / 0.005 ms
- 18: [ 128, 1, 32] PERMUTE q-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.000 / 0.000 ms
- 19: [ 32, 1, 32] MUL_MAT kq-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.013 / 0.013 ms
- 20: [ 32, 1, 32] SCALE kq_scaled-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.008 / 0.008 ms
- 21: [ 32, 1, 32] ADD kq_masked-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.005 / 0.005 ms
- 22: [ 32, 1, 32] SOFT_MAX kq_soft_max-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.006 / 0.006 ms
- 23: [ 128, 1, 32] MUL_MAT kqv-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.011 / 0.011 ms
- 24: [ 128, 32, 1] PERMUTE kqv_merged-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.001 / 0.001 ms
- 25: [ 4096, 1, 1] CONT kqv_merged_cont-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.004 / 0.004 ms
- 26: [ 4096, 1, 1] MUL_MAT kqv_out-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.047 / 0.047 ms
- 27: [ 4096, 1, 1] ADD ffn_inp-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.007 / 0.007 ms
- 28: [ 4096, 1, 1] RMS_NORM norm-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.005 / 0.005 ms
- 29: [ 4096, 1, 1] MUL ffn_norm-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.007 / 0.007 ms
- 30: [ 1024, 1, 1] MUL_MAT mlp_pre_hidden-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.022 / 0.022 ms
- 31: [ 1024, 1, 1] UNARY mlp_pre_relu-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.005 / 0.005 ms
- 32: [ 11008, 1, 1] MUL_MAT mlp_pre_out-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.035 / 0.035 ms
- 33: [ 11008, 1, 1] MUL_MAT_SPARSE ffn_gate_sparse-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.025 / 0.025 ms
- 34: [ 11008, 1, 1] UNARY ffn_gate_act-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.005 / 0.005 ms
- 35: [ 11008, 1, 1] MUL_MAT_SPARSE ffn_up_sparse-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.023 / 0.023 ms
- 36: [ 11008, 1, 1] MUL ffn_gate_par-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.005 / 0.005 ms
- 37: [ 4096, 1, 1] AXPY ffn_down_sparse-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.040 / 0.040 ms
- 38: [ 4096, 1, 1] ADD l_out-0 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.005 / 0.005 ms
- 39: [ 4096, 1, 1] RMS_NORM norm-1 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.005 / 0.005 ms
- 40: [ 4096, 1, 1] MUL attn_norm-1 ( 1) cpu = 0.000 / 0.000 ms, wall = 0.005 / 0.005 ms
...
We can see that CPU time always 0, which shows we mostly didn’t run something on CPU
So, go for the next step, we need to figure out where invoke so many unexpected Memcpy call(exact code line).
4. Code traceability
First, refered with profiling result, we can see all unexcepted Memcpy are Host2Device. I learned about coda/hip api about memcpy:

I used CTRL+F to search all memcpy action and hipMemcpyKind kind to locate potential code line.
Then I inserted some useless hip-api function near them:
# Use cudaDeviceSynchronize to mark this piece of code for further profiling
static void ggml_backend_cuda_set_tensor_async(ggml_backend_t backend, ggml_tensor * tensor, const void * data, size_t offset, size_t size) {
GGML_ASSERT(offset + size <= ggml_nbytes(tensor) && "tensor write out of bounds");
GGML_ASSERT(tensor->data != NULL && "tensor not allocated");
GGML_ASSERT(tensor->backend == GGML_BACKEND_GPU);
cudaDeviceSynchronize();
CUDA_CHECK(cudaMemcpyAsync((char *)tensor->data + offset, data, size, cudaMemcpyHostToDevice, g_cudaStreams[g_main_device][0]));
cudaDeviceSynchronize();
UNUSED(backend);
}
# Use Malloc&free to mark this piece of code for further profiling
void* dummy_ptr = nullptr;
cudaMalloc(&dummy_ptr, 1);
if (dummy_ptr != nullptr) {
CUDA_CHECK(cudaFree(dummy_ptr));
dummy_ptr = nullptr;
}
const char * x = src_ptr + i1_low*nb1 + i2*nb2 + i3*nb3;
if (nb0 == ts && nb1 == ts*ne0/bs) {return cudaMemcpyAsync(dst_ptr, x, i1_diff*nb1, kind, stream);}
else if (nb0 == ts) {return cudaMemcpy2DAsync(dst_ptr, ts*ne0/bs, x, nb1, ts*ne0/bs, i1_diff, kind, stream);} else {
for (int64_t i1 = 0; i1 < i1_diff; i1++) {
const void * rx = (const void *) ((const char *) x + i1*nb1);
void * rd = (void *) (dst_ptr + i1*ts*ne0/bs);
cudaError_t r = cudaMemcpy2DAsync(rd, ts/bs, rx, nb0, ts/bs, ne0, kind, stream);
if (r != cudaSuccess) return r;
}
return cudaSuccess;
}
Then profile it again, I got the following result:
backend_cuda_set_with_devicesync.pftrace:
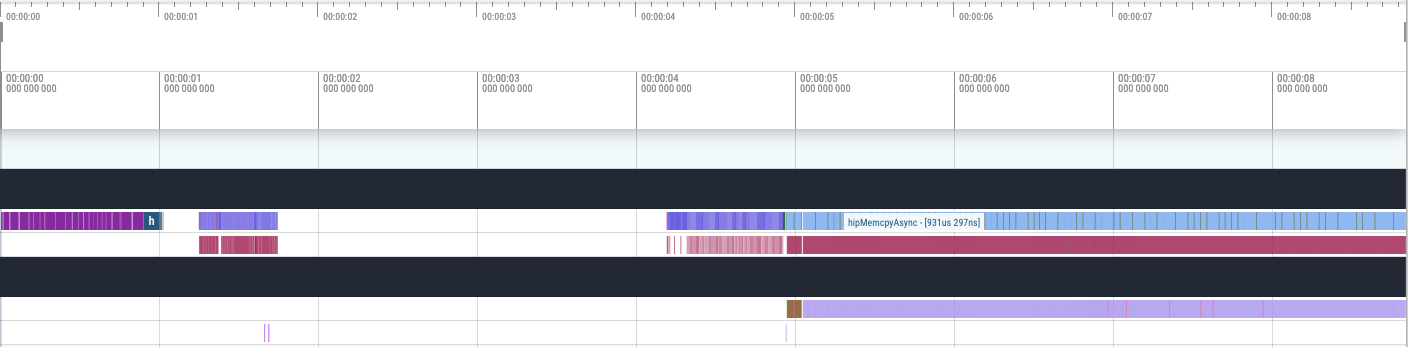
backend_cuda_set_without_devicesync.pftrace:

cpy_tensor_2d_with_mallocfree.pftrace:

We can see HipFree label showed in this test, which means this function caused unexpected memcpy:
static cudaError_t ggml_cuda_cpy_tensor_2d(
void * dst, const struct ggml_tensor * src, int64_t i3, int64_t i2, int64_t i1_low, int64_t i1_high, cudaStream_t stream) {
cudaMemcpyKind kind;
char * src_ptr;
if (src->backend == GGML_BACKEND_CPU) {
kind = cudaMemcpyHostToDevice;
src_ptr = (char *) src->data;
} else if (src->backend == GGML_BACKEND_GPU || src->backend == GGML_BACKEND_GPU_SPLIT) {
GGML_ASSERT(src->backend != GGML_BACKEND_GPU_SPLIT || (i1_low == 0 && i1_high == src->ne[1]));
kind = cudaMemcpyDeviceToDevice;
ggml_tensor_extra_gpu * extra = (ggml_tensor_extra_gpu *) src->extra;
int id;
CUDA_CHECK(cudaGetDevice(&id));
src_ptr = (char *) extra->data_device[id];
} else {
GGML_ASSERT(false);
}
char * dst_ptr = (char *) dst;
const int64_t ne0 = src->ne[0];
const int64_t nb0 = src->nb[0];
const int64_t nb1 = src->nb[1];
const int64_t nb2 = src->nb[2];
const int64_t nb3 = src->nb[3];
const enum ggml_type type = src->type;
const int64_t ts = ggml_type_size(type);
const int64_t bs = ggml_blck_size(type);
int64_t i1_diff = i1_high - i1_low;
const char * x = src_ptr + i1_low*nb1 + i2*nb2 + i3*nb3;
if (nb0 == ts && nb1 == ts*ne0/bs) {
return cudaMemcpyAsync(dst_ptr, x, i1_diff*nb1, kind, stream);
} else if (nb0 == ts) {
return cudaMemcpy2DAsync(dst_ptr, ts*ne0/bs, x, nb1, ts*ne0/bs, i1_diff, kind, stream);
} else {
for (int64_t i1 = 0; i1 < i1_diff; i1++) {
const void * rx = (const void *) ((const char *) x + i1*nb1);
void * rd = (void *) (dst_ptr + i1*ts*ne0/bs);
// pretend the row is a matrix with cols=1
cudaError_t r = cudaMemcpy2DAsync(rd, ts/bs, rx, nb0, ts/bs, ne0, kind, stream);
if (r != cudaSuccess) return r;
}
return cudaSuccess;
}
}
To get finer-grain result, I profiled deeper for two functions:
matmul_src1_cpytensor_mallocfree.pftrace:

No HipFree label, which means not this function caused unexpected memcpy.
matmul_src0_cpytensor_mallocfree.pftrace:

No HipFree label, which means not this function caused unexpected memcpy.
src0_cuda_op_flatten_mallocfree.pftrace:

No HipFree label, which means not this function caused unexpected memcpy.
src1_cuda_op_flatten_mallocfree.pftrace:

We can see HipFree label showed in this test, which means this piece of code caused unexpected memcpy:
if (use_src1 && !src1_stays_on_host) {
if (src1_on_device) {
src1_ddf = (float *) src1_extra->data_device[g_main_device];
} else {
src1_ddf = (float *) ggml_cuda_pool_malloc(ggml_nbytes(src1), &src1_asf);
CUDA_CHECK(ggml_cuda_cpy_tensor_2d(src1_ddf, src1, 0, 0, 0, nrows1, main_stream));
}
}
5. Unexpected memcpy eliminate
This exception is mainly caused by the ffn_norm_weight, which is a bug in the project itself. The project logic automatically selects which parameters to put on the GPU based on the size of the graphics memory. However, the norm weight was previously placed in a specific class, and everything in that class will be placed on the CPU no matter what. Therefore, this leads to memcpy behavior from the CPU to the GPU every time these parameters are used. The corresponding solution is to change the storage in the class to a different location so that it can also enter the GPU during the initial load, instead of using memcpy from the CPU every time it is used.
After bug fix, we got the following result:

Unfortunately, the problem remains unresolved. But specifically, we have identified the essence of the problem: operators. From HipStream, we can see that the operation of the kernel is continuous, which proves that the reason for poor performance is not in the MemcpyAsync we have verified, but in the poor implementation of the operator. To solve this problem, we must find the typical operator with the worst performance and optimize the corresponding operator.
6. Operator optimization
Operator optimization is a heavy work, so we first structed a statistical data for running time:
Name Calls Percentage TotalDurationMs AverageMs
0 Cijk_Alik_Bljk_HB_MT32x32x32_MI16x16x16x1_SN_1... 5888 56.977682 492.232145 0.083599
1 void dequantize_mul_mat_vec<1, 1, &(convert_f1... 1452 14.746984 127.399699 0.087740
2 Cijk_Alik_Bljk_HB_MT32x32x32_MI16x16x16x1_SN_1... 1288 9.408184 81.277628 0.063103
3 void dequantize_block<1, 1, &(convert_f32(void... 10370 3.461931 29.907737 0.002884
4 void dequantize_block<1, 1, &(convert_f16(void... 10370 2.742961 23.696530 0.002285
5 void rms_norm_f32<1024>(float const*, float*, ... 2990 1.774599 15.330825 0.005127
6 add_f32(float const*, float const*, float*, in... 4416 1.403729 12.126866 0.002746
7 void rope<float, true>(float const*, float*, i... 2944 1.329179 11.482825 0.003900
8 Cijk_Alik_Bljk_HB_MT32x32x32_MI16x16x16x1_SN_1... 184 1.019050 8.803607 0.047845
9 void cpy_f32_f16<&(cpy_1_f32_f16(char const*, ... 2944 1.014060 8.760496 0.002975
10 Cijk_Alik_Bljk_HB_MT32x32x16_MI16x16x16x1_SN_1... 1472 1.012366 8.745866 0.005941
11 mul_f32(float const*, float const*, float*, in... 2990 0.999206 8.632172 0.002887
12 Cijk_Alik_Bljk_HB_MT32x32x32_MI16x16x16x1_SN_1... 1408 0.798503 6.898291 0.004899
13 Cijk_Alik_Bljk_HB_MT64x64x32_MI16x16x16x1_SN_1... 52 0.734857 6.348453 0.122085
14 soft_max_f32(float const*, float*, int) [clone... 1472 0.642171 5.547740 0.003768
15 void cpy_f32_f16<&(cpy_1_f32_f32(char const*, ... 1472 0.444675 3.841566 0.002609
16 scale_f32(float const*, float*, float, int) [c... 1472 0.429947 3.714326 0.002523
17 relu_f32(float const*, float*, int) [clone .kd] 1472 0.391271 3.380202 0.002296
18 __amd_rocclr_fillBufferAligned.kd 6 0.328644 2.839166 0.473194
19 Cijk_Alik_Bljk_HB_MT64x64x32_MI16x16x16x1_SN_1... 2 0.153582 1.326803 0.663401
20 Cijk_Alik_Bljk_HB_MT64x64x32_MI16x16x16x1_SN_1... 12 0.123283 1.065044 0.088753
21 Cijk_Alik_Bljk_HB_GB_MT32x32x32_MI16x16x16x1_S... 64 0.040560 0.350400 0.005475
22 k_compute_batched_ptrs(__half const*, __half c... 64 0.022577 0.195040 0.003047
Cijk_Alik_Bljk… functions are internal rocblas/hipblas calls, which come from AMD’s Tensile library: https://github.com/ROCm/Tensile. It’s realatively hard to optimize directly. So we targeted the operator about mul_mat_vec, that is, attention part. To be more specific, mul_mat_vec_q4_0_q8_1_cuda():
static void mul_mat_vec_q4_0_q8_1_cuda(const void * vx, const void * vy, float * dst, const int ncols, const int nrows, cudaStream_t stream) {
GGML_ASSERT(ncols % QK4_0 == 0);
const int block_num_y = (nrows + GGML_CUDA_MMV_Y - 1) / GGML_CUDA_MMV_Y;
const dim3 block_nums(block_num_y, 1, 1);
const dim3 block_dims(WARP_SIZE, GGML_CUDA_MMV_Y, 1);
mul_mat_vec_q<QK4_0, QI4_0, block_q4_0, VDR_Q4_0_Q8_1_MMVQ, vec_dot_q4_0_q8_1>
<<<block_nums, block_dims, 0, stream>>>(vx, vy, dst, ncols, nrows);
}
static void mul_mat_vec_q4_0_q8_1_cuda(const void * vx, const void * vy, float * dst, const int ncols, const int nrows, cudaStream_t stream, const int *lst, const float *idx) {
GGML_ASSERT(ncols % QK4_0 == 0);
const int block_num_y = (nrows + GGML_CUDA_MMV_Y - 1) / GGML_CUDA_MMV_Y;
const dim3 block_nums(block_num_y, 1, 1);
const dim3 block_dims(WARP_SIZE, GGML_CUDA_MMV_Y, 1);
mul_mat_vec_q<QK4_0, QI4_0, block_q4_0, VDR_Q4_0_Q8_1_MMVQ, vec_dot_q4_0_q8_1>
<<<block_nums, block_dims, 0, stream>>>(vx, vy, dst, ncols, nrows, lst, idx);
}
Then we insert some timing code for both 4090 and 7900 on both Llama.cpp project and PowerInfer project to compare the results:
static void ggml_cuda_op_mul_mat(
const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst, ggml_cuda_op_mul_mat_t op,
const bool convert_src1_to_q8_1) {
uint64_t t1 = ggml_time_us();
uint64_t t2 = ggml_time_us();
uint64_t t3 = ggml_time_us();
uint64_t t4 = ggml_time_us();
...
cudaDeviceSynchronize();
t2 = ggml_time_us();
// do the computation
op(src0, src1, dst, src0_dd_i, src1_ddf_i, src1_ddq_i, dst_dd_i,
row_low[id], row_high[id], src1_ncols, src1_padded_col_size, stream);
CUDA_CHECK(cudaGetLastError());
cudaDeviceSynchronize();
t3 = ggml_time_us();
...
cudaDeviceSynchronize();
t4 = ggml_time_us();
if (dst->ne[0] == 4096 && dst->ne[1] == 1 && dst->src[0]->ne[0] == 4096) {
printf("transfer src to gpu %ld us\n", t2-t1);
printf("computation on gpu %ld us\n", t3-t2);
printf("write back %ld us\n", t4-t3);
}
}
The result are as follows(Both on Q4 model, mistral-7b with llama, bamboo-base-7b with PowerInfer):
| Llama + 4090 | Llama + 7900 | PowerInfer + 4090 | PowerInfer + 7900 | |
|---|---|---|---|---|
| Transfer to GPU | 4us | 25us | 0us | 17-71us |
| Computation on G | 14us | 31us | 7us | 33-308us |
| Write back | 1us | 0us | 14us | 0-1us |
This is consistent with the results we obtained from our previous tests, where 7900 performed stably and fast in the llama.cpp project and had no significant fluctuations in running time. However, the computation time fluctuation of 7900 in the PowerInfer project is severe, which is the root cause of its poor performance.
Next step is to analyze why this significant fluctuations happened on the 7900 and PowerInfer project.
We consider that the most likely reason is the difference caused by the different parameters passed in each op operation, so we added loop runs with the same parameters to the op operation to verify our hypothesis:
static void ggml_cuda_op_mul_mat(
const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst, ggml_cuda_op_mul_mat_t op,
const bool convert_src1_to_q8_1) {
uint64_t t1 = ggml_time_us();
uint64_t t2 = ggml_time_us();
uint64_t t3 = ggml_time_us();
uint64_t t4 = ggml_time_us();
...
// do the computation
for(int i = 0; i < 7; i++)
{
printf("round %d\n",i);
cudaDeviceSynchronize();
t2 = ggml_time_us();
op(src0, src1, dst, src0_dd_i, src1_ddf_i, src1_ddq_i, dst_dd_i,
row_low[id], row_high[id], src1_ncols, src1_padded_col_size, stream);
CUDA_CHECK(cudaGetLastError());
cudaDeviceSynchronize();
t3 = ggml_time_us();
printf("computation on gpu %ld us, src0_name: %s, src1_name: %s\n", t3-t2, src0->name, src1->name);
}
...
}
We got the following result:
round 0
computation on gpu 118 us, src0_name: blk.0.attn_v.weight, src1_name: attn_norm-0
round 1
computation on gpu 35 us, src0_name: blk.0.attn_v.weight, src1_name: attn_norm-0
round 2
computation on gpu 34 us, src0_name: blk.0.attn_v.weight, src1_name: attn_norm-0
round 3
computation on gpu 34 us, src0_name: blk.0.attn_v.weight, src1_name: attn_norm-0
round 4
computation on gpu 34 us, src0_name: blk.0.attn_v.weight, src1_name: attn_norm-0
round 5
computation on gpu 34 us, src0_name: blk.0.attn_v.weight, src1_name: attn_norm-0
round 6
computation on gpu 35 us, src0_name: blk.0.attn_v.weight, src1_name: attn_norm-0
round 0
computation on gpu 97 us, src0_name: blk.0.attn_k.weight, src1_name: attn_norm-0
round 1
computation on gpu 34 us, src0_name: blk.0.attn_k.weight, src1_name: attn_norm-0
round 2
computation on gpu 34 us, src0_name: blk.0.attn_k.weight, src1_name: attn_norm-0
round 3
computation on gpu 34 us, src0_name: blk.0.attn_k.weight, src1_name: attn_norm-0
round 4
computation on gpu 34 us, src0_name: blk.0.attn_k.weight, src1_name: attn_norm-0
round 5
computation on gpu 33 us, src0_name: blk.0.attn_k.weight, src1_name: attn_norm-0
round 6
computation on gpu 34 us, src0_name: blk.0.attn_k.weight, src1_name: attn_norm-0
round 0
computation on gpu 122 us, src0_name: blk.0.attn_q.weight, src1_name: attn_norm-0
round 1
computation on gpu 26 us, src0_name: blk.0.attn_q.weight, src1_name: attn_norm-0
round 2
computation on gpu 26 us, src0_name: blk.0.attn_q.weight, src1_name: attn_norm-0
round 3
computation on gpu 25 us, src0_name: blk.0.attn_q.weight, src1_name: attn_norm-0
round 4
computation on gpu 25 us, src0_name: blk.0.attn_q.weight, src1_name: attn_norm-0
round 5
computation on gpu 25 us, src0_name: blk.0.attn_q.weight, src1_name: attn_norm-0
round 6
computation on gpu 25 us, src0_name: blk.0.attn_q.weight, src1_name: attn_norm-0
round 0
computation on gpu 67 us, src0_name: blk.0.attn_output.weight, src1_name: kqv_merged_cont-0
round 1
computation on gpu 25 us, src0_name: blk.0.attn_output.weight, src1_name: kqv_merged_cont-0
round 2
computation on gpu 24 us, src0_name: blk.0.attn_output.weight, src1_name: kqv_merged_cont-0
round 3
computation on gpu 25 us, src0_name: blk.0.attn_output.weight, src1_name: kqv_merged_cont-0
round 4
computation on gpu 25 us, src0_name: blk.0.attn_output.weight, src1_name: kqv_merged_cont-0
round 5
computation on gpu 25 us, src0_name: blk.0.attn_output.weight, src1_name: kqv_merged_cont-0
round 6
computation on gpu 25 us, src0_name: blk.0.attn_output.weight, src1_name: kqv_merged_cont-0
round 0
computation on gpu 34 us, src0_name: blk.0.fc1.weight, src1_name: ffn_inp-0
round 1
computation on gpu 21 us, src0_name: blk.0.fc1.weight, src1_name: ffn_inp-0
round 2
computation on gpu 21 us, src0_name: blk.0.fc1.weight, src1_name: ffn_inp-0
round 3
computation on gpu 21 us, src0_name: blk.0.fc1.weight, src1_name: ffn_inp-0
round 4
computation on gpu 21 us, src0_name: blk.0.fc1.weight, src1_name: ffn_inp-0
round 5
computation on gpu 21 us, src0_name: blk.0.fc1.weight, src1_name: ffn_inp-0
round 6
computation on gpu 20 us, src0_name: blk.0.fc1.weight, src1_name: ffn_inp-0
round 0
computation on gpu 49 us, src0_name: blk.0.fc2.weight, src1_name: mlp_pre_relu-0
round 1
computation on gpu 23 us, src0_name: blk.0.fc2.weight, src1_name: mlp_pre_relu-0
round 2
computation on gpu 23 us, src0_name: blk.0.fc2.weight, src1_name: mlp_pre_relu-0
round 3
computation on gpu 23 us, src0_name: blk.0.fc2.weight, src1_name: mlp_pre_relu-0
round 4
computation on gpu 23 us, src0_name: blk.0.fc2.weight, src1_name: mlp_pre_relu-0
round 5
computation on gpu 23 us, src0_name: blk.0.fc2.weight, src1_name: mlp_pre_relu-0
round 6
computation on gpu 23 us, src0_name: blk.0.fc2.weight, src1_name: mlp_pre_relu-0
round 0
computation on gpu 48 us, src0_name: blk.0.ffn_gate.weight, src1_name: ffn_norm-0
round 1
computation on gpu 27 us, src0_name: blk.0.ffn_gate.weight, src1_name: ffn_norm-0
round 2
computation on gpu 27 us, src0_name: blk.0.ffn_gate.weight, src1_name: ffn_norm-0
round 3
computation on gpu 29 us, src0_name: blk.0.ffn_gate.weight, src1_name: ffn_norm-0
round 4
computation on gpu 27 us, src0_name: blk.0.ffn_gate.weight, src1_name: ffn_norm-0
round 5
computation on gpu 27 us, src0_name: blk.0.ffn_gate.weight, src1_name: ffn_norm-0
round 6
computation on gpu 27 us, src0_name: blk.0.ffn_gate.weight, src1_name: ffn_norm-0
round 0
computation on gpu 44 us, src0_name: blk.0.ffn_up.weight, src1_name: ffn_norm-0
round 1
computation on gpu 29 us, src0_name: blk.0.ffn_up.weight, src1_name: ffn_norm-0
round 2
computation on gpu 28 us, src0_name: blk.0.ffn_up.weight, src1_name: ffn_norm-0
round 3
computation on gpu 27 us, src0_name: blk.0.ffn_up.weight, src1_name: ffn_norm-0
round 4
computation on gpu 28 us, src0_name: blk.0.ffn_up.weight, src1_name: ffn_norm-0
round 5
computation on gpu 28 us, src0_name: blk.0.ffn_up.weight, src1_name: ffn_norm-0
round 6
computation on gpu 27 us, src0_name: blk.0.ffn_up.weight, src1_name: ffn_norm-0
round 0
computation on gpu 310 us, src0_name: blk.0.ffn_down_t.weight, src1_name: ffn_gate_par-0
round 1
computation on gpu 302 us, src0_name: blk.0.ffn_down_t.weight, src1_name: ffn_gate_par-0
round 2
computation on gpu 323 us, src0_name: blk.0.ffn_down_t.weight, src1_name: ffn_gate_par-0
round 3
computation on gpu 330 us, src0_name: blk.0.ffn_down_t.weight, src1_name: ffn_gate_par-0
round 4
computation on gpu 281 us, src0_name: blk.0.ffn_down_t.weight, src1_name: ffn_gate_par-0
round 5
computation on gpu 326 us, src0_name: blk.0.ffn_down_t.weight, src1_name: ffn_gate_par-0
round 6
computation on gpu 285 us, src0_name: blk.0.ffn_down_t.weight, src1_name: ffn_gate_par-0
computation on gpu 35 us, src0_name: blk.0.attn_v.weight, src1_name: attn_norm-0
computation on gpu 34 us, src0_name: blk.0.attn_k.weight, src1_name: attn_norm-0
computation on gpu 26 us, src0_name: blk.0.attn_q.weight, src1_name: attn_norm-0
computation on gpu 25 us, src0_name: blk.0.attn_output.weight, src1_name: kqv_merged_cont-0
computation on gpu 21 us, src0_name: blk.0.fc1.weight, src1_name: ffn_inp-0
computation on gpu 23 us, src0_name: blk.0.fc2.weight, src1_name: mlp_pre_relu-0
computation on gpu 27 us, src0_name: blk.0.ffn_gate.weight, src1_name: ffn_norm-0
computation on gpu 29 us, src0_name: blk.0.ffn_up.weight, src1_name: ffn_norm-0
computation on gpu 302 us, src0_name: blk.0.ffn_down_t.weight, src1_name: ffn_gate_par-0
At this point, the problem has finally narrowed down to the specific operator problem, which is the sparse operator problem independently implemented in the PowerInfer project.
static void dequantize_axpy_vec_q4_0_cuda(const void * vx, const dfloat * y, float * dst, const int ncols, const int nrows, cudaStream_t stream) {
GGML_ASSERT(ncols % GGML_CUDA_DMMV_X == 0);
const int block_num_y = (nrows + GGML_CUDA_MMV_Y - 1) / GGML_CUDA_MMV_Y;
const dim3 block_nums(1, block_num_y, 1);
const dim3 block_dims(WARP_SIZE, GGML_CUDA_MMV_Y, 1);
dequantize_mul_mat_axpy<QK4_0, QR4_0, dequantize_q4_0>
<<<block_nums, block_dims, ncols*sizeof(float), stream>>>(vx, y, dst, ncols, nrows);
}
static void dequantize_axpy_sparse_vec_q4_0_cuda(const void * vx, const dfloat * y, float * dst, const int ncols, const int nrows, cudaStream_t stream, int *lst, float *idx) {
GGML_ASSERT(ncols % GGML_CUDA_DMMV_X == 0);
const int block_num_y = (nrows + GGML_CUDA_MMV_Y - 1) / GGML_CUDA_MMV_Y;
const dim3 block_nums(1, block_num_y, 1);
const dim3 block_dims(WARP_SIZE, GGML_CUDA_MMV_Y, 1);
dequantize_mul_mat_axpy_sparse<QK4_0, QR4_0, dequantize_q4_0>
<<<block_nums, block_dims, ncols*sizeof(float), stream>>>(vx, y, dst, ncols, nrows, lst, idx);
}
kernel function is:
template <int qk, int qr, dequantize_kernel_t dequantize_kernel>
static __global__ void dequantize_mul_mat_axpy_sparse(const void * __restrict__ vx, const dfloat * __restrict__ y, float * __restrict__ dst, const int ncols, const int nrows, int *lst, float *idx) {
const int gpu_row = blockIdx.y*blockDim.y + threadIdx.y;
if (gpu_row >= nrows) {
return;
}
int row = lst ? lst[gpu_row] : gpu_row;
const int tid = threadIdx.x;
short *d = (short *)((char *)vx + ncols * gpu_row * 2);
if (y[row] == 0)
return;
if (idx[row] < dev_sparse_threshold) {
return;
}
const int bid = blockIdx.y;
extern __shared__ float shared_dst[];
const int iter_stride = 2*GGML_CUDA_DMMV_X;
const int vals_per_iter = iter_stride / WARP_SIZE;
const int y_offset = qr == 1 ? 1 : qk/2;
// partial sum for each thread
float tmp = 0.0f;
for (int i = 0; i < ncols; i += GGML_CUDA_DMMV_X) {
shared_dst[i+tid] = 0;
}
__syncthreads();
for (int i = 0; i < ncols; i += iter_stride) {
const int col = i + vals_per_iter*tid;
const int ib = (gpu_row*ncols + col)/qk; // x block index
const int iqs = (col%qk)/qr; // x quant index
const int iybs = col - col%qk; // y block start index
// processing >2 values per i iter is faster for fast GPUs
#pragma unroll
for (int j = 0; j < vals_per_iter; j += 2) {
dfloat2 v;
dequantize_kernel(vx, ib, iqs + j/qr, v);
tmp = v.x * y[row];
shared_dst[iybs + iqs + j/qr + 0] = tmp;
tmp = v.y * y[row];
shared_dst[iybs + iqs + j/qr + y_offset] = tmp;
}
}
__syncthreads();
for (int i = 0; i < ncols; i += GGML_CUDA_DMMV_X) {
atomicAdd(&dst[i+tid], shared_dst[i+tid]);
// dst[i+tid] = shared_dst[i+tid]
}
}
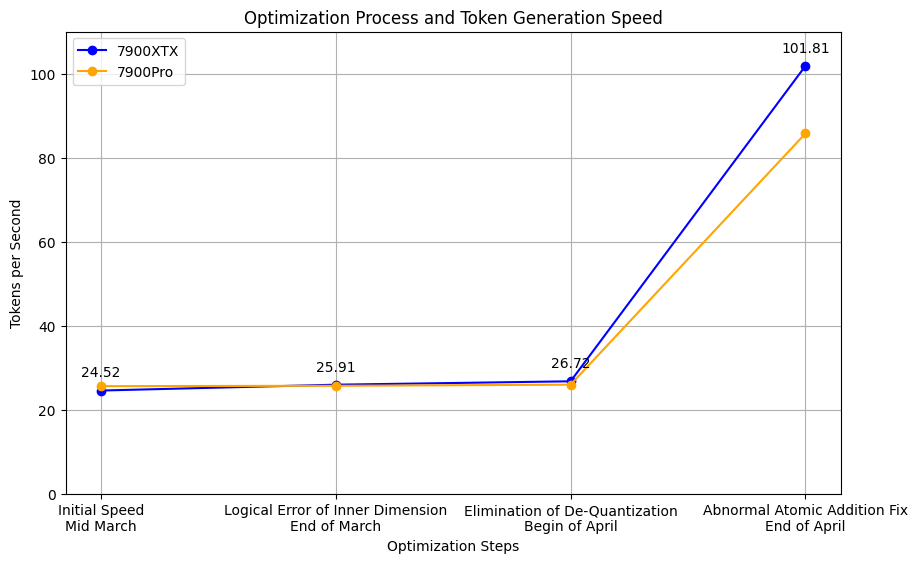
In this operator, I noticed that the final atomicadd operation was very suspicious, and further, I replaced it with dst[i+tid] += shared_dst[i+tid]; Obviously, this will yield the wrong answer, but it will validate performance issues. As we expected, after replacement, the performance has increased from 40 token/s to 85 token/s. This is a very obvious bottleneck.
As shown in the above figure, there is no performance difference between nvidia and amd on atomicadd, so we speculate that the root cause of the performance problem is: When multiple threads attempt to access the same position in the local memory dst array simultaneously, it leads to decreased concurrency, almost linearly.
Algorithm optimization:
Before:
template <int qk, int qr, dequantize_kernel_t dequantize_kernel>
static __global__ void dequantize_mul_mat_axpy_sparse(const void * __restrict__ vx, const dfloat * __restrict__ y, float * __restrict__ dst, const int ncols, const int nrows, int *lst, float *idx) {
// qk = quantized weights per x block
// qr = number of quantized weights per data value in x block
const int gpu_row = blockIdx.y*blockDim.y + threadIdx.y;
if (gpu_row >= nrows) {
return;
}
int row = lst ? lst[gpu_row] : gpu_row;
const int tid = threadIdx.x;
short *d = (short *)((char *)vx + ncols * gpu_row * 2);
if (y[row] == 0)
return;
if (idx[row] < dev_sparse_threshold) {
return;
}
const int bid = blockIdx.y;
extern __shared__ float shared_dst[]; // TODO:dynamic
const int iter_stride = 2*GGML_CUDA_DMMV_X;
const int vals_per_iter = iter_stride / WARP_SIZE; // num quantized vals per thread and i iter
const int y_offset = qr == 1 ? 1 : qk/2;
// partial sum for each thread
float tmp = 0.0f;
for (int i = 0; i < ncols; i += GGML_CUDA_DMMV_X) {
shared_dst[i+tid] = 0;
}
__syncthreads();
for (int i = 0; i < ncols; i += iter_stride) {
const int col = i + vals_per_iter*tid;
const int ib = (gpu_row*ncols + col)/qk; // x block index
const int iqs = (col%qk)/qr; // x quant index
const int iybs = col - col%qk; // y block start index
// processing >2 values per i iter is faster for fast GPUs
#pragma unroll
for (int j = 0; j < vals_per_iter; j += 2) {
// process 2 vals per j iter
// dequantize
// for qr = 2 the iqs needs to increase by 1 per j iter because 2 weights per data val
dfloat2 v;
dequantize_kernel(vx, ib, iqs + j/qr, v);
// matrix multiplication
// for qr = 2 the y index needs to increase by 1 per j iter because of y_offset = qk/2
tmp = v.x * y[row];
shared_dst[iybs + iqs + j/qr + 0] = tmp;
tmp = v.y * y[row];
shared_dst[iybs + iqs + j/qr + y_offset] = tmp;
}
}
__syncthreads();
for (int i = 0; i < ncols; i += GGML_CUDA_DMMV_X) {
atomicAdd(&dst[i+tid], shared_dst[i+tid]);
}
}
static void dequantize_axpy_sparse_batch_q4_0_cuda(const void * vx, const dfloat * y, float * dst, const int ncols, const int nrows, int src1_rows, int src1_ncols, cudaStream_t stream, int *lst, float *idx) {
GGML_ASSERT(ncols % GGML_CUDA_DMMV_X == 0);
const int block_num_y = (nrows + GGML_CUDA_MMV_Y - 1) / GGML_CUDA_MMV_Y;
const dim3 block_nums(1, block_num_y, 1);
const dim3 block_dims(WARP_SIZE, GGML_CUDA_MMV_Y, 1);
dequantize_mul_mat_axpy_sparse_batch<QK4_0, QR4_0, dequantize_q4_0>
<<<block_nums, block_dims, ncols*sizeof(float), stream>>>(vx, y, dst, ncols, nrows, src1_rows, src1_ncols, lst, idx);
}
After:
template <int qk, int qr, dequantize_kernel_t dequantize_kernel>
static __global__ void my_1col_new_dequantize_mul_mat_axpy_sparse_batch(const void * __restrict__ vx, const dfloat * __restrict__ y, float * __restrict__ dst, const int ncols, const int nrows, int *lst, float *idx) {
// printf("in 1col kernel\n");
int warp_id = threadIdx.y;
int tid = threadIdx.x + blockIdx.x * 32;
int col = tid * 2;
dfloat2 v;
int iqs = (col % qk) / qr;
float tmp[2];
tmp[0] = 0.0;
tmp[1] = 0.0;
__shared__ float res[64];
res[threadIdx.x] = 0.0;
res[threadIdx.x + 32] = 0.0;
#pragma unroll 32
for (int row = warp_id; row < nrows; row += 32) {
int raw_row = row;
// int raw_row = row;
dfloat y_row = y[raw_row];
if (y_row == 0.0) {
continue;
}
const int ib = (row * ncols + col) / qk;
dequantize_kernel(vx, ib, iqs, v);
tmp[0] += v.x * y_row;
tmp[1] += v.y * y_row;
}
const int adder_loc = threadIdx.x % 16 + threadIdx.x / 16 * 32;
atomicAdd(res + adder_loc, tmp[0]);
atomicAdd(res + adder_loc + 16, tmp[1]);
__syncthreads();
if (warp_id <= 1) {
int write_back_loc = warp_id * 32 + threadIdx.x;
dst[write_back_loc + blockIdx.x * 64] = res[write_back_loc];
}
}
static void dequantize_axpy_sparse_vec_q4_0_cuda(const void * vx, const dfloat * y, float * dst, const int ncols, const int nrows, cudaStream_t stream, int *lst, float *idx) {
GGML_ASSERT(ncols % GGML_CUDA_DMMV_X == 0);
const dim3 block_dim = dim3(32, 32);
const int block_num = ncols / 64;
my_1col_new_dequantize_mul_mat_axpy_sparse_batch<QK4_0, QR4_0, dequantize_q4_0>
<<<block_num, block_dim, 0, stream>>>(vx, y, dst, ncols, nrows, lst, idx);
}
7. Final Optimization Result
7. Future Work
We avoided atomicadd as much as possible through algorithms, but the objective fact is that AMD devices perform extremely poorly in situations of high concurrency atomicadd, while Nvidia’s support is very good. This may be due to the lack of efficiency in implementing AMD atomicadd; It may also be because the compiler under the AMD toolchain is not intelligent enough to handle similar scenarios. And finding a more specific reason is that the follow-up project is worth doing, which is enough to significantly improve the efficiency of AMD machines in general scenarios.